Note
This tutorial can be used interactively with Google Colab! You can also click here to run the Jupyter notebook locally.

Making your Hardware Accelerator TVM-ready with UMA¶
Authors: Michael J. Klaiber, Christoph Gerum, Paul Palomero Bernardo
This is an introductory tutorial to the Universal Modular Accelerator Interface (UMA). UMA provides an easy-to-use API to integrate new hardware accelerators into TVM.
This tutorial gives you step-by-step guidance how to use UMA to make your hardware accelerator TVM-ready. While there is no one-fits-all solution for this problem, UMA targets to provide a stable and Python-only API to integrate a number of hardware accelerator classes into TVM.
In this tutorial you will get to know the UMA API in three use cases of increasing complexity. In these use case the three mock-accelerators Vanilla, Strawberry and Chocolate are introduced and integrated into TVM using UMA.
Vanilla¶
Vanilla is a simple accelerator consisting of a MAC array and has no internal memory. It is can ONLY process Conv2D layers, all other layers are executed on a CPU, that also orchestrates Vanilla. Both the CPU and Vanilla use a shared memory.
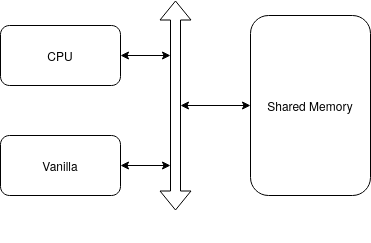
Vanilla has a C interface vanilla_conv2dnchw(...)` for carrying out a Conv2D operation (including same-padding),
that accepts pointers to input feature map, weights and result,
as well as the dimensions of Conv2D: oc, iw, ih, ic, kh, kw.
int vanilla_conv2dnchw(float* ifmap, float* weights, float* result, int oc, int iw, int ih, int ic, int kh, int kw);
The script uma_cli creates code skeletons with API-calls into the UMA-API for new accelerators.
For Vanilla we use it as follows: (--tutorial vanilla adds all the additional files required for this part of the tutorial)
pip install inflection
cd $TVM_HOME/apps/uma
python uma_cli.py --add_hardware vanilla_accelerator --tutorial vanilla
uma_cli.py generates these files in the directory vanilla_accelerator which we are going to revisit.
backend.py
codegen.py
conv2dnchw.cc
passes.py
patterns.py
run.py
strategies.py
Vanilla backend
The generated backend for vanilla is found in vanilla_accelerator/backend.py:
class VanillaAcceleratorBackend(UMABackend):
"""UMA backend for VanillaAccelerator."""
def __init__(self):
super().__init__()
self._register_pattern("conv2d", conv2d_pattern())
self._register_tir_pass(PassPhase.TIR_PHASE_0, VanillaAcceleratorConv2DPass())
self._register_codegen(fmt="c", includes=gen_includes)
@property
def target_name(self):
return "vanilla_accelerator"
Define offloaded patterns
To specify that Conv2D is offloaded to Vanilla, it is described as Relay dataflow pattern (DFPattern) in vanilla_accelerator/patterns.py
def conv2d_pattern():
pattern = is_op("nn.conv2d")(wildcard(), wildcard())
pattern = pattern.has_attr({"strides": [1, 1]})
return pattern
To map Conv2D operations from the input graph to Vanilla’s
low level function call vanilla_conv2dnchw(...), the TIR pass
VanillaAcceleratorConv2DPass (that will be discussed later in this tutorial)
is registered in VanillaAcceleratorBackend.
Codegen
The file vanilla_accelerator/codegen.py defines static C-code that is added to the
resulting C-Code generated by TVMś C-Codegen in gen_includes.
Here C-code is added to include Vanilla’s low level library``vanilla_conv2dnchw()``.
def gen_includes() -> str:
topdir = pathlib.Path(__file__).parent.absolute()
includes = ""
includes += f'#include "{topdir}/conv2dnchw.cc"'
return includes
As shown above in VanillaAcceleratorBackend it is registered to UMA with the self._register_codegen
self._register_codegen(fmt="c", includes=gen_includes)
Building the Neural Network and run it on Vanilla
To demonstrate UMA’s functionality, we will generate C code for a single Conv2D layer and run it on
the Vanilla accelerator.
The file vanilla_accelerator/run.py provides a demo running a Conv2D layer
making use of Vanilla’s C-API.
def main():
mod, inputs, output_list, runner = create_conv2d()
uma_backend = VanillaAcceleratorBackend()
uma_backend.register()
mod = uma_backend.partition(mod)
target = tvm.target.Target("vanilla_accelerator", host=tvm.target.Target("c"))
export_directory = tvm.contrib.utils.tempdir(keep_for_debug=True).path
print(f"Generated files are in {export_directory}")
compile_and_run(
AOTModel(module=mod, inputs=inputs, outputs=output_list),
runner,
interface_api="c",
use_unpacked_api=True,
target=target,
test_dir=str(export_directory),
)
main()
By running vanilla_accelerator/run.py the output files are generated in the model library format (MLF).
Output:
Generated files are in /tmp/tvm-debug-mode-tempdirs/2022-07-13T13-26-22___x5u76h0p/00000
Let’s examine the generated files:
Output:
cd /tmp/tvm-debug-mode-tempdirs/2022-07-13T13-26-22___x5u76h0p/00000
cd build/
ls -1
codegen
lib.tar
metadata.json
parameters
runtime
src
To evaluate the generated C code go to codegen/host/src/default_lib2.c
cd codegen/host/src/
ls -1
default_lib0.c
default_lib1.c
default_lib2.c
In default_lib2.c you can now see that the generated code calls into Vanilla’s C-API and executes a Conv2D layer:
TVM_DLL int32_t tvmgen_default_vanilla_accelerator_main_0(float* placeholder, float* placeholder1, float* conv2d_nchw, uint8_t* global_workspace_1_var) {
vanilla_accelerator_conv2dnchw(placeholder, placeholder1, conv2d_nchw, 32, 14, 14, 32, 3, 3);
return 0;
}
Strawberry¶
Coming soon …
Chocolate¶
Coming soon …
Request for Community Input¶
If this tutorial did not fit to your accelerator, lease add your requirements to the UMA thread in the TVM discuss forum: Link. We are eager to extend this tutorial to provide guidance on making further classes of AI hardware accelerators TVM-ready using the UMA interface.
References¶
[UMA-RFC] UMA: Universal Modular Accelerator Interface, TVM RFC, June 2022.
[DFPattern] Pattern Matching in Relay