TVM: An End to End IR Stack for Deploying Deep Learning Workloads on Hardware Platforms
Tianqi Chen(project lead), Thierry Moreau(hardware stack), Ziheng Jiang†(graph compilation), Haichen Shen(gpu optimization)
Advisors: Luis Ceze, Carlos Guestrin, Arvind Krishnamurthy
Paul G. Allen School of Computer Science & Engineering, University of Washington
DMLC open-source community
†Amazon Web Service
Deep learning has become ubiquitous and indispensable. Part of this revolution has been fueled by scalable deep learning systems, such as TensorFlow, MXNet, Caffe and PyTorch. Most existing systems are optimized for a narrow range of server-class GPUs, and require significant effort be deployed on other platforms such as mobile phones, IoT devices and specialized accelerators (FPGAs, ASICs). As the number of deep learning frameworks and hardware backends increase, we propose a unified intermediate representation (IR) stack that will close the gap between the productivity-focused deep learning frameworks, and the performance- or efficiency-oriented hardware backends.

We are excited to announce the launch of TVM as solution to this problem. TVM is a novel framework that can:
- Represent and optimize the common deep learning computation workloads for CPUs, GPUs and other specialized hardware
- Automatically transform the computation graph to minimize memory utilization, optimize data layout and fuse computation patterns
- Provide an end-to-end compilation from existing front-end frameworks down to bare-metal hardware, all the way up to browser executable javascripts.
With the help of TVM, we can easily run deep learning workloads on mobile phones, embedded devices and even the browser with little additional effort. TVM also provides a unified optimization framework for deep learning workloads on a multitude of hardware platforms, including specialized accelerators that rely on novel computational primitives.
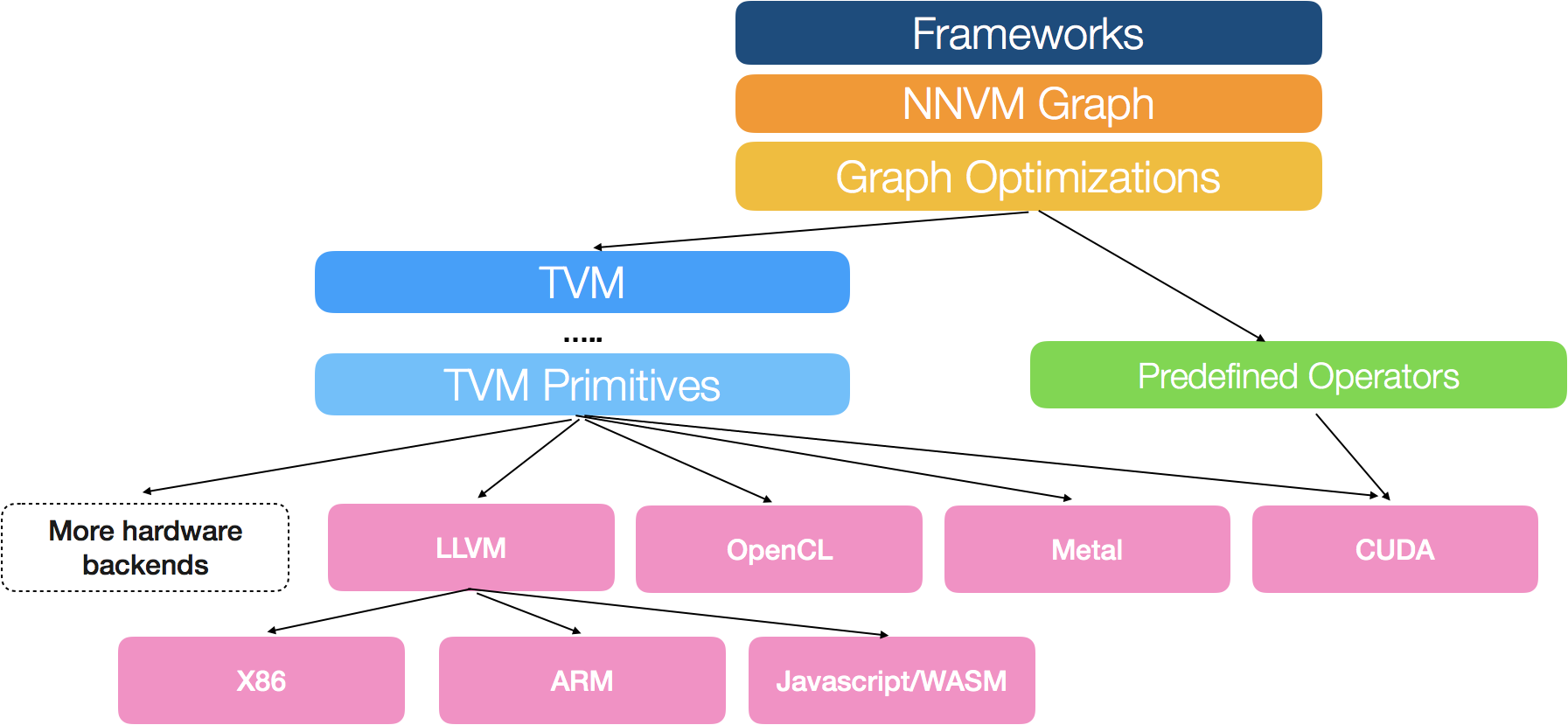
We adopt a common philosophy from the compiler community and provide two intermediate representation layers to efficiently lower high-level deep learning algorithms down to a multitude of hardware back-ends.
In today’s release, we open-source TVM package that contains optimization primitives for x86, ARM, OpenCL, Metal, CUDA and Javascript. We are actively working on adding support for specialized hardware acceleration and Nvidia’s GEMM-optimized Volta architecture.
Technical Details
The goal of TVM stack is to provide a reusable toolchain to compile high-level neural network descriptions from deep learning framework frontends down to low-level machine code for multiple hardware backends. Take Apache MXNet as a front-end example, the following code snippet demonstrates how can TVM be used to compile a high-level description of a deep learning model to an optimized executable module tailored to the target hardware.

The challenge lies in enabling support for multiple hardware back-ends while keeping compute, memory and energy footprints at their lowest. We borrow wisdom from the compiler community in order to bridge the gap between the multitude of deep learning frameworks and hardware back-ends: we build a two-level intermediate layer composed of NNVM, a high-level intermediate representation (IR) for task scheduling and memory management, and TVM, an expressive low-level IR for optimizing compute kernels.
The first level of the stack is a computational graph based representation. A computation graph is a directed acyclic graph that represent computation as nodes and dataflow dependency as edges. This representation is very powerful: it allows us to bake operation attributes into the computation graph and specify transformation rules to iteratively optimize a computation graph. This is a common approach taken by most of the existing deep learning frameworks, including the NNVM graph representation in TVM stack, TensorFlow XLA and Intel’s ngraph.

A lot of powerful optimizations can be supported by the graph optimization framework. For example, we provided a sublinear memory optimization functionality that allows user to train 1000 layers of ImageNet ResNet on a single GPU.
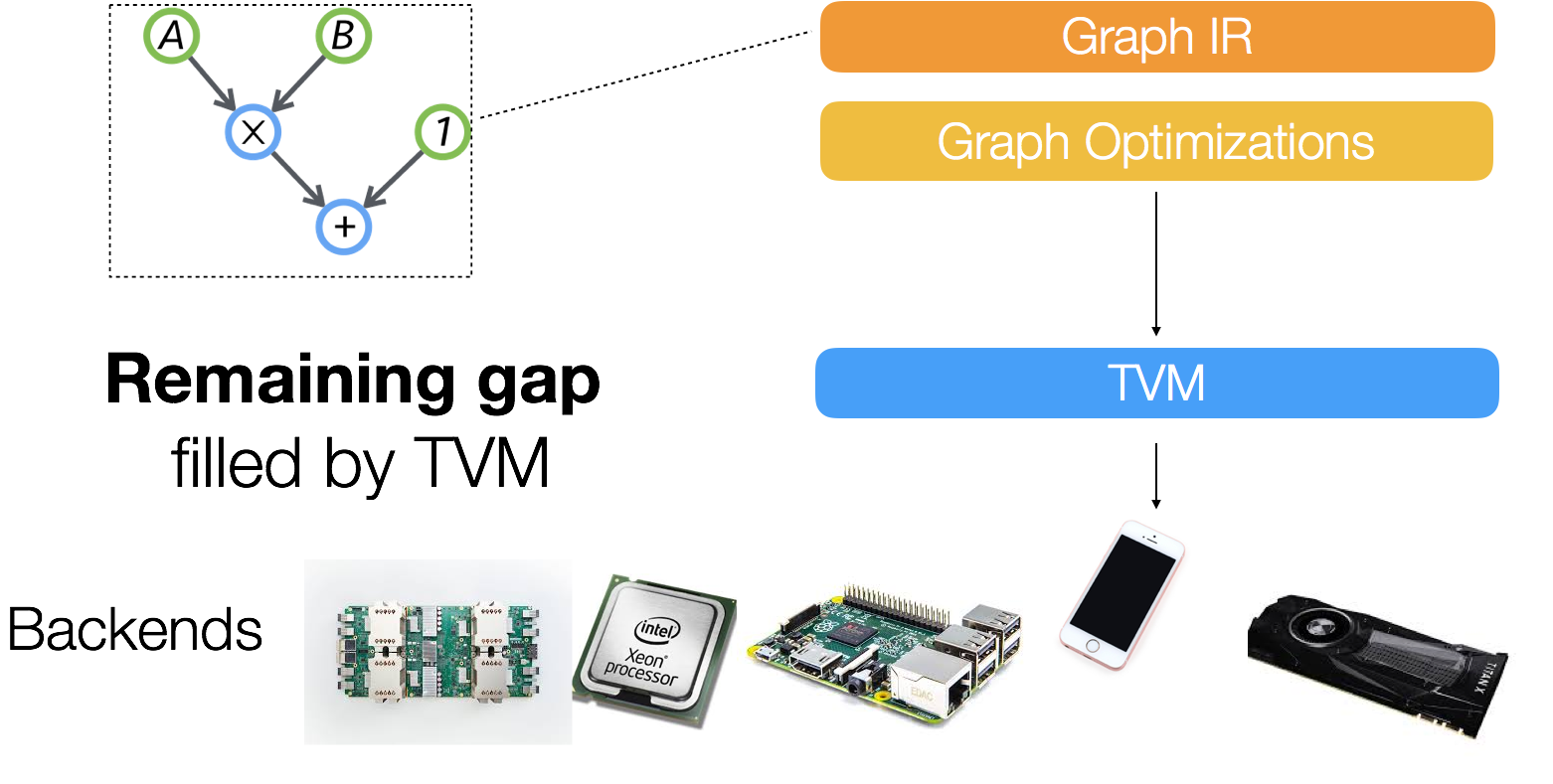
However, we find that the computational graph based IR alone is not enough to solve the challenge of supporting different hardware backends. The reason being that a single graph operator like convolution or matrix multiplication may be mapped and optimized in very different ways for each hardware back-end. These hardware-specific optimizations can vary drastically in terms of memory layout, parallelization threading patterns, caching access patterns and choice of hardware primitives. We want to be able to explicitly express these optimization knobs in a common representation to efficiently navigate the optimization space.
We build a low level representation to solve this problem. This representation is based on index formula, with additional support for recurrence computation.

The low level IR adopt principles from existing image processing languages like Halide or darkroom to formulate an expressive deep learning DSL. TVM builds low level optimizations inspired by loop transformation tools like loopy and polyhedra-based analysis. We also draw inspiration from the dataflow description languages used in deep learning frameworks like MXNet, TensorFlow, Theano. The algorithms described in TVM are then processed in a scheduling phase to apply transformations that are tailored to the target hardware back-end.
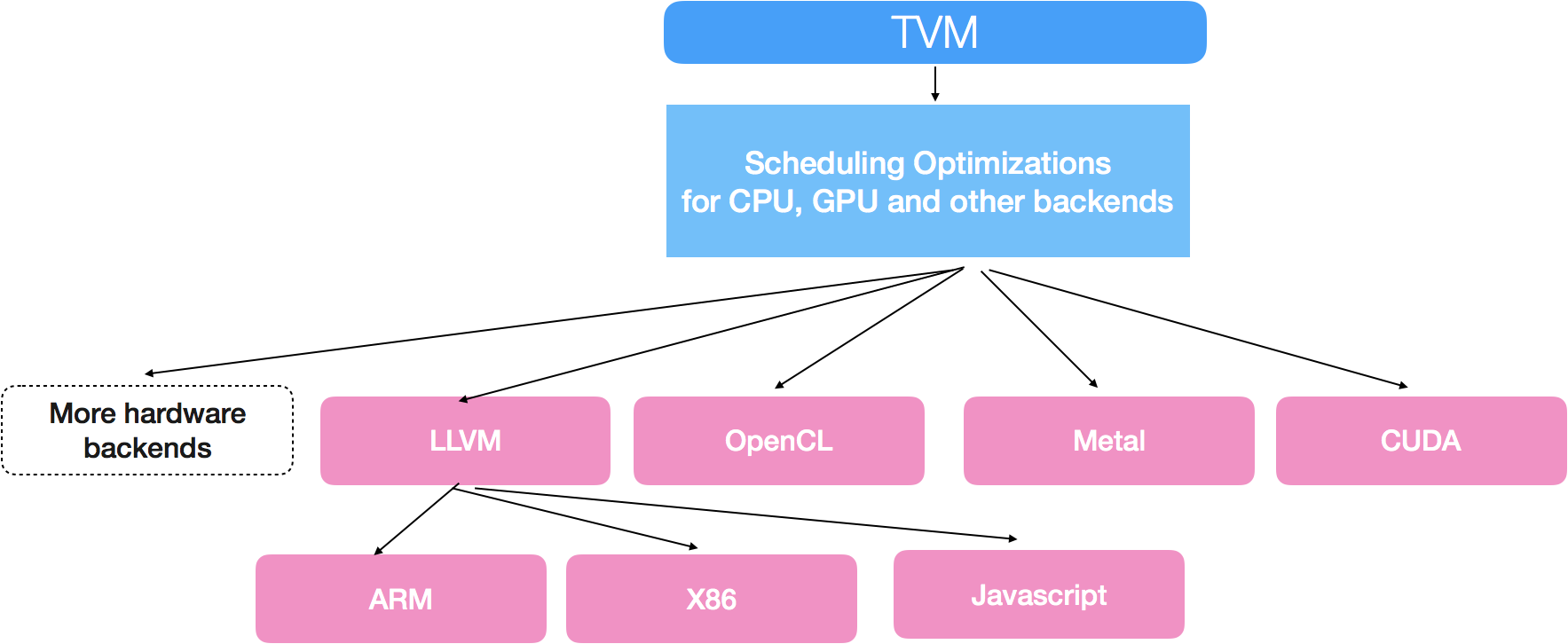
TVM includes standard transformation primitives commonly found in CPU optimization frameworks. More importantly, TVM incorporates novel optimization primitives targeted at GPUs, by exploiting thread cooperation patterns, data layout transformations and powerful new compute primitives. Using TVM in combination with NNVM provides an rich opportunity to optimize deep learning workloads across the software stack, enabling joint compute graph-level and operator-level optimizations.
Multi-language and Platform Support
One of the many strength of TVM lies in its rich support for multiple platforms and languages. We present two components of the framework: the compiler stack which contains complete optimization libraries to produce optimized machine code, and the runtime which is lightweight and offers the portability required to deploy the compiled modules on different platforms.
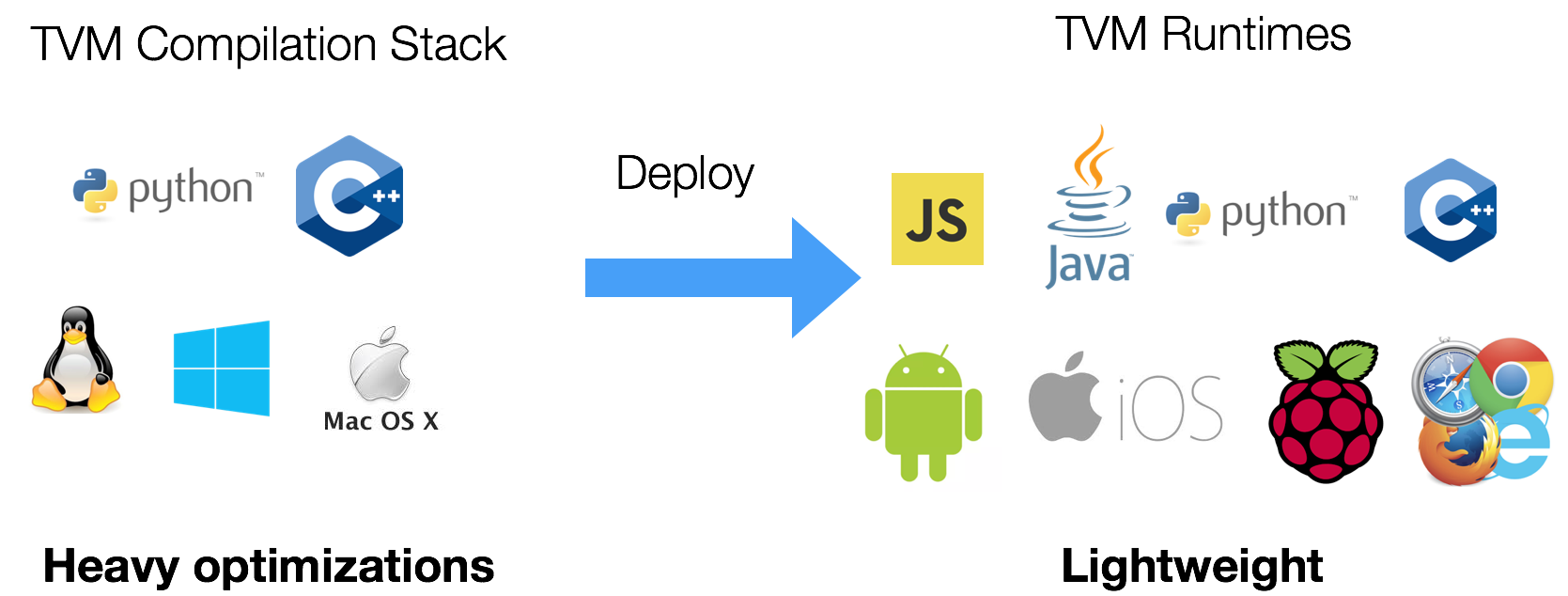
TVM currently support a python and C++ interface to the embedded compiler stack. We design the framework with maximum re-use in mind, so that the compiler stack improvements can be applied interchangeably between the Python and C++ components.
We also provide a lightweight runtime that can directly run TVM compiled code in languages such as javascript, java, python, and c++ on platforms including android, iOS, raspberry pi and web browsers.
Remote Deployment and Execution
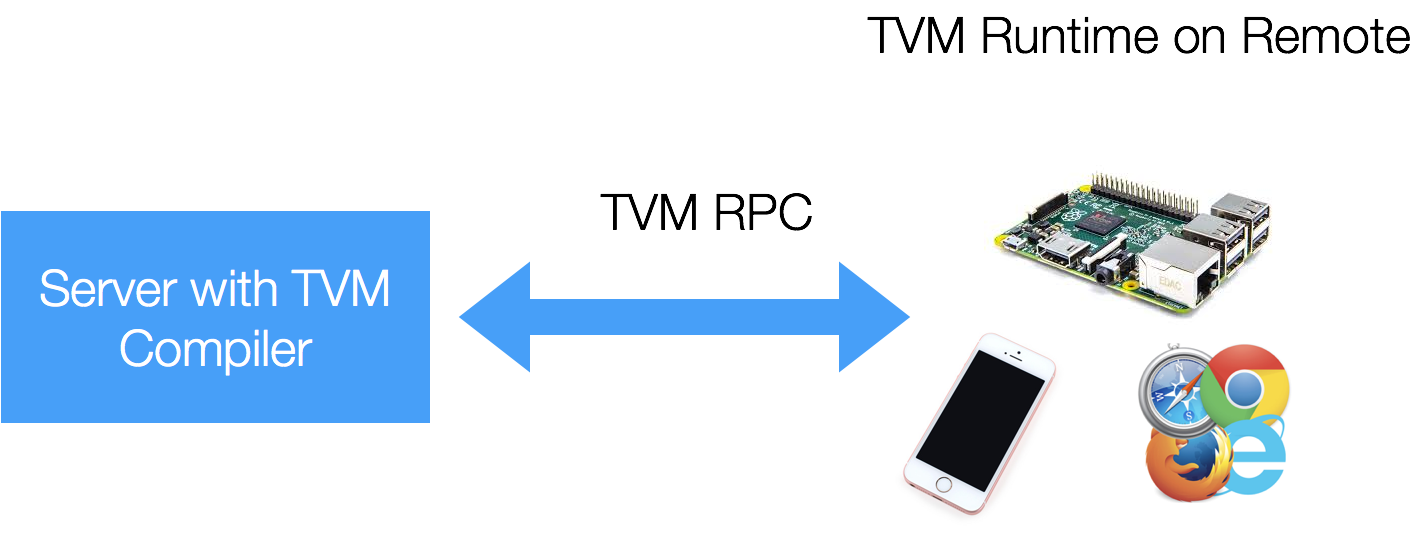
TVM supports cross-compilation for and testing embedded devices with TVM RPC, a lightweight interface to deploy and execute TVM cross-compiled modules on a remote embedded device. This provides a familiar high-level Python interface to the TVM user to compile, optimize and test deep learning algorithms remotely on various low-level embedded devices.
Performance
TVM is still in an early stage of development and we can expect more improvements to come, but we have started to see very promising results, which are discussed in this section.
TVM gives us the flexibility to explore the rich optimization space of various deep learning kernels, for multiple hardware platforms. For instance, TVM allows us to tailor data layout and fused pattern requirements for the kernels and platforms that we most care about. Please note that the baseline libraries are created for more general purpose problems, while TVM’s optimized kernels are heavily tuned for the workloads we evaluated via an auto-tuning process. TVM serves as a bridge to quickly generate obtain such specialized kernels.
The results listed in this section are still work in progress, and there is room for improvement.
Raspberry Pi
In the first part of result we compared the TVM CPU schedule to nnpack on a raspberry Pi 3B executing a resnet workload. Due to limited time, we utilized TVM to implemented the direct convolution while nnpack was used to perform winograd conv for 3x3 kernels.
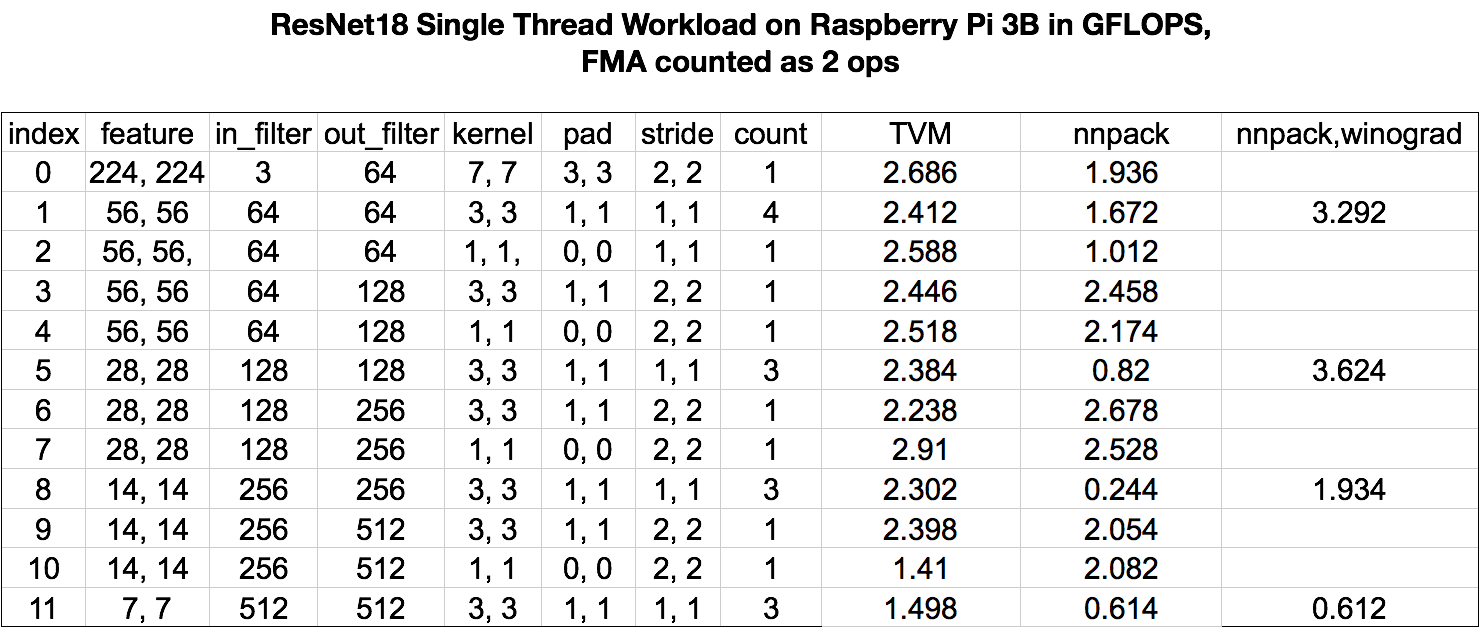
We can find that with TVM’s autotuned kernels, we can obtain performance similar to the hand-optimized kernels in nnpack for the raspberry pi experiments.
GPU Results
Author Credit These benchmarks and corresponding schedule optimizations are created by our contributors: Leyuan Wang (AWS / UCDavis), Yuwei Hu(TuSimple) and Weitang Liu (AWS/ UCDavis). They deserve all the credits.
As a proof of concept, we created an end to end compilation pipeline that can compile MxNet models down to TVM execution graphs. We apply optimization within and between graph nodes by automatically fusing operators together and letting TVM generate the fused kernels. We benchmarked the mobilenet ImageNet workload, and discuss the results below:
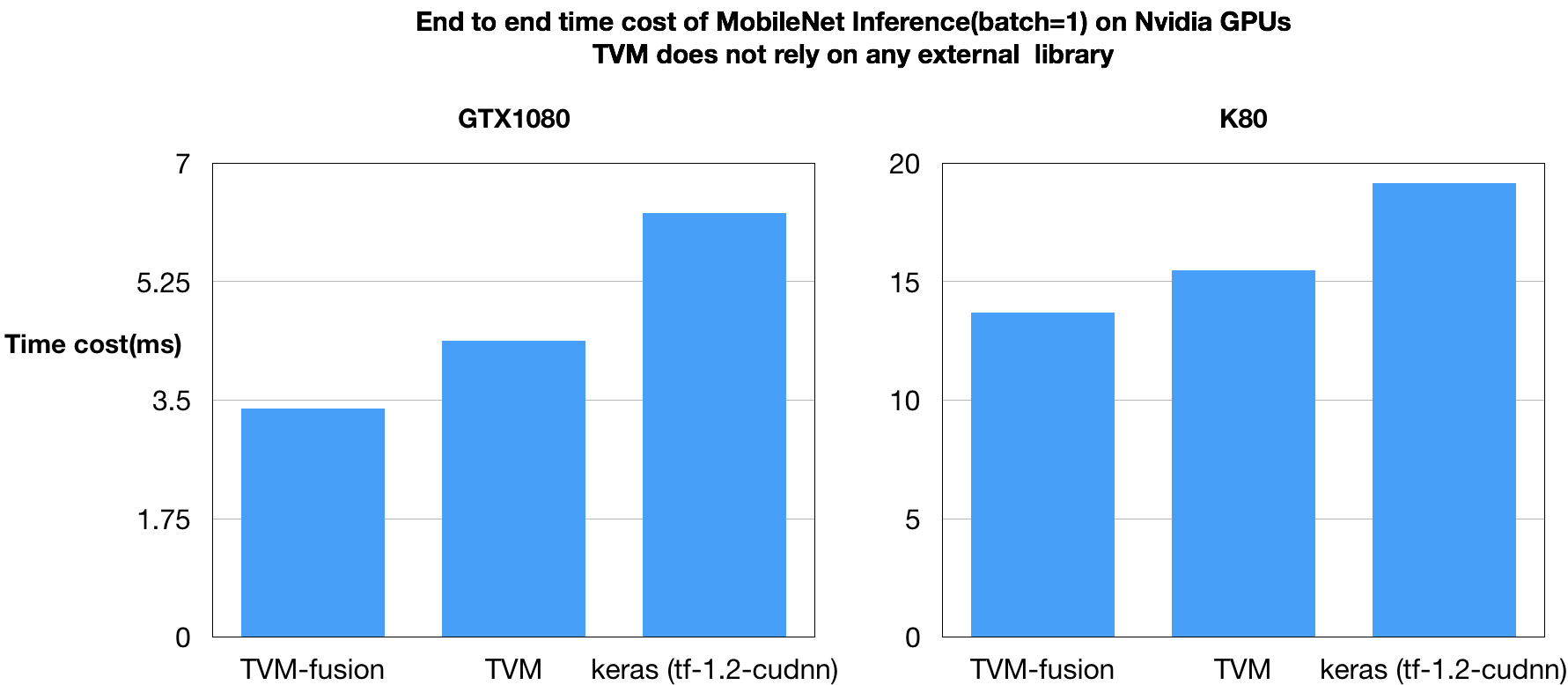
We can find that TVM can outperform our baseline method in terms of speed. More interestingly, the kernel fusion brings additional speedup. It is worth mentioning that TVM generates all the optimized GPU kernels on its own without relying on external libraries like CuDNN.
We are working on more experiments and will release new results as they are obtained.
Open Source Effort
TVM started as a research project of Paul G. Allen School Computer Science and Engineering at University of Washington. The TVM stack is designed to support DLPack, a consensus on tensor data structure by multiple major deep learning frameworks. We have received early contributions from from UW, AWS, Qiho 360, Facebook, HKUST, TuSimple, UCDavis, SJTU as well members of DMLC open-source community and DLPack initiative. Going forward, the project will follow the Apache open-source model, to create a community maintained project. You are more than welcome to join us and lead the effort.
Acknowledgement
This project wouldn’t become possible without our early contributors. We would like to thank Yizhi Liu(Qihoo 360), Yuwei Hu(TuSimple), Xingjian Shi(HKUST), Leyuan Wang(AWS/UCDavis), Nicolas Vasilache(Facebook), Jian Weng(UCLA), Weitang Liu(AWS/UCDavis), Edward Z. Yang(Facebook), Lianmin Zheng(SJTU), Qiao Zhang(UW), William Moses(Facebook/MIT) and Hu Shiwen. The author would also like to thank Xianyi Zhang(PerfXLab) for helpful discussions.
We also learnt a lot from the following projects when building TVM.
- Halide: TVM uses HalideIR as data structure for arithematic simplification and low level lowering. HalideIR is derived from Halide. We also learns from Halide when implementing the lowering pipeline in TVM.
- Loopy: use of integer set analysis and its loop transformation primitives.
- Theano: the design inspiration of symbolic scan operator for recurrence.
Source code
- Github page can be found here: https://github.com/dmlc/tvm
- TVM is DLPack compatible, which makes it easy to support frameworks that adopts the standard, such as MXNet, PyTorch, Caffe2 and tiny-dnn.