Paul G. Allen School of Computer Science & Engineering, University of Washington
Amazon Web Service AI team
DMLC open-source community
Deep learning has become ubiquitous and indispensable. We are seeing a rising need for deploying deep learning workloads on many kinds of platforms such as mobile phones, GPU, IoT devices and specialized accelerators. Last month, we announced TVM stack to close the gap between deep learning frameworks, and the performance- or efficiency-oriented hardware backends. TVM stack makes it easy to build an end to end compilation for a deep learning framework. However, we think it would even be better to have a unified solution that works for all frameworks.
Today, UW Allen school and AWS AI team, together with other contributors, are excited to announce the release of NNVM compiler, an open deep learning compiler to compile front-end framework workloads directly to hardware backends. We build it using the two-level intermediate representation(IR) in the TVM stack. The reader is welcome to refer to the original TVM announcement for more technical details about TVM stack. With the help of TVM stack, NNVM compiler can:
- Represent and optimize the common deep learning workloads in high level graph IR
- Transform the computation graph to minimize memory utilization, optimize data layout and fuse computation patterns for different hardware backends.
- Present an end to end compilation pipeline from front-end deep learning frameworks to bare metal hardwares.
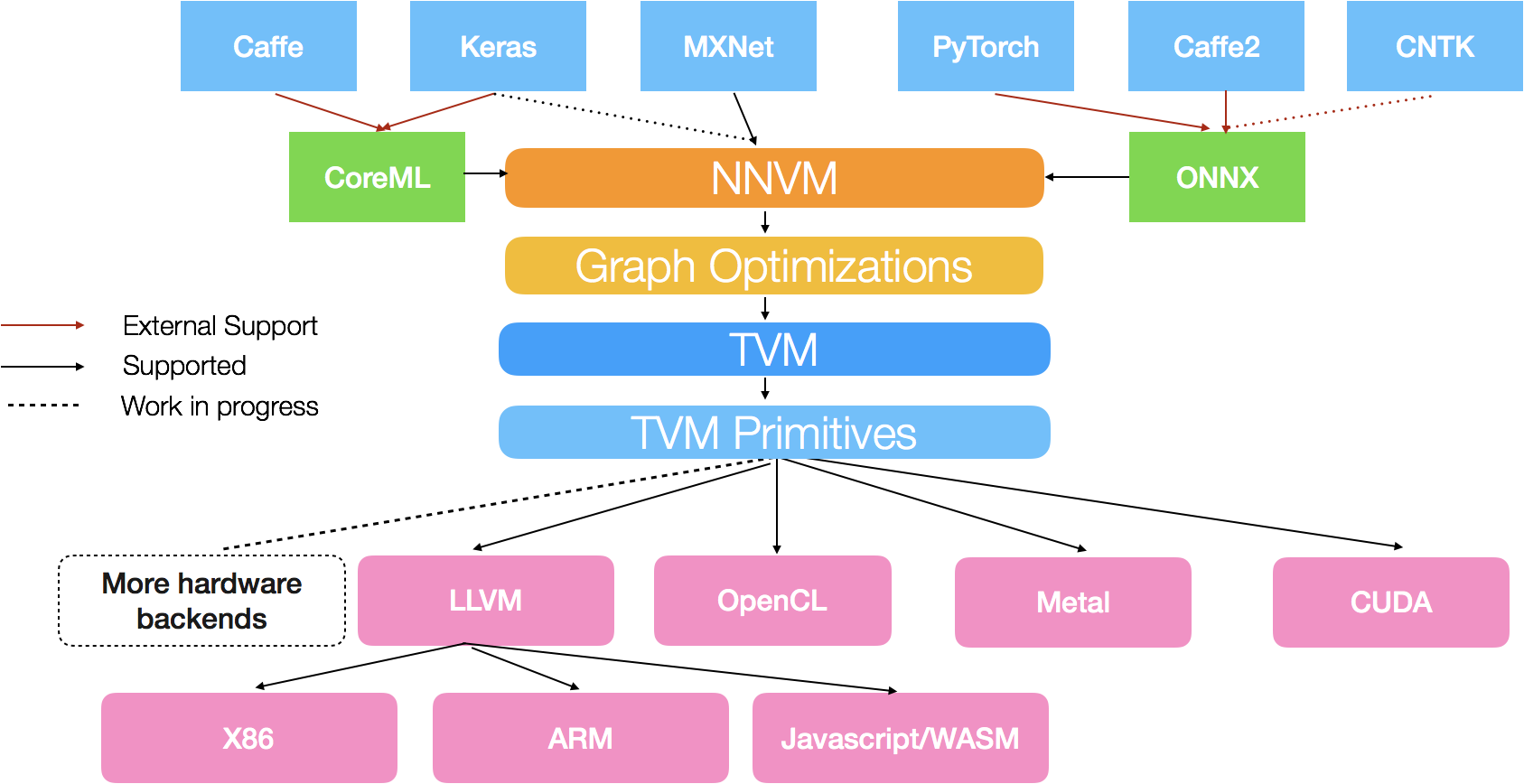
The NNVM compiler can directly take models from deep learning frameworks such as Apache MXNet. It also support model exchange formats such as ONNX and CoreML. ONNX support enables NNVM to compile deep learning models from PyTorch, Caffe2 and CNTK. The CoreML frontend enables deployment of CoreML models to non-iOS devices.

Separation of Optimization and Deployment
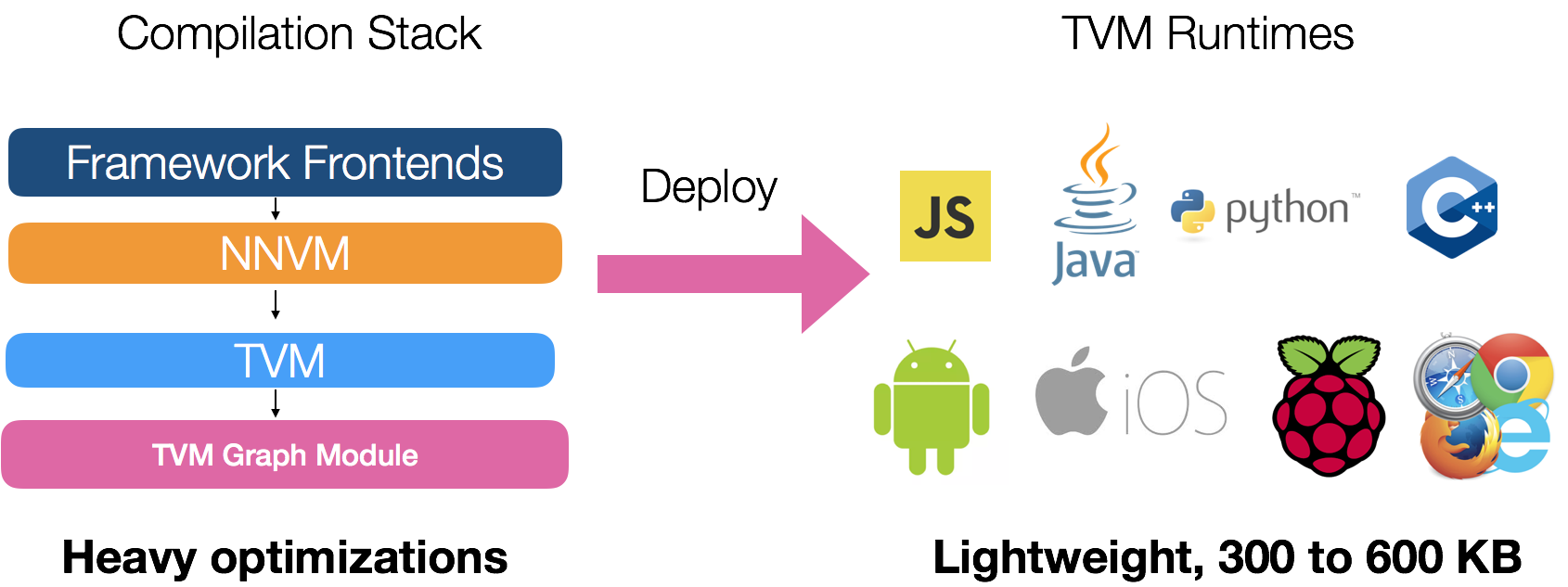
NNVM compiler applies graph level and tensor level optimizations and jointly optimize them to get the best performance. We take a different approach from existing deep learning frameworks, which packages the graph optimization with the deployment runtime. NNVM compiler adopts the conventional wisdom from compiler to separate the optimization from the actual deployment runtime. This approach offers substantial optimization but still keeps the runtime lightweight. The compiled module only depend on a minimum TVM runtime that only takes around 300KB when deployed on a Raspberry Pi or mobile devices.
Performance
NNVM compiler is still under active development, and we can expect more improvements to come, but we have started to see promising results. We benchmarked its performance and compared it against Apache MXNet on two typical hardware configurations: ARM CPU on Raspberry PI and Nvidia GPU on AWS. Despite the radical architecture difference between these two chips, we can use the same infrastructure and only need to change the schedule for each type of hardware.
Nvidia GPU
GPU benchmarks and schedules are contributed by Leyuan Wang (AWS/UCDavis) and Yuwei Hu (TuSimple). We compared the NNVM compiler against Apache MXNet with CUDA8 and cuDNN7 as the backend on Nvidia K80. This is a very strong baseline, as Apache MXNet turns on auto-tuning to select the best kernel from CuDNN. We also used the optimized depthwise kernel in MXNet to optimize MobileNet workload.
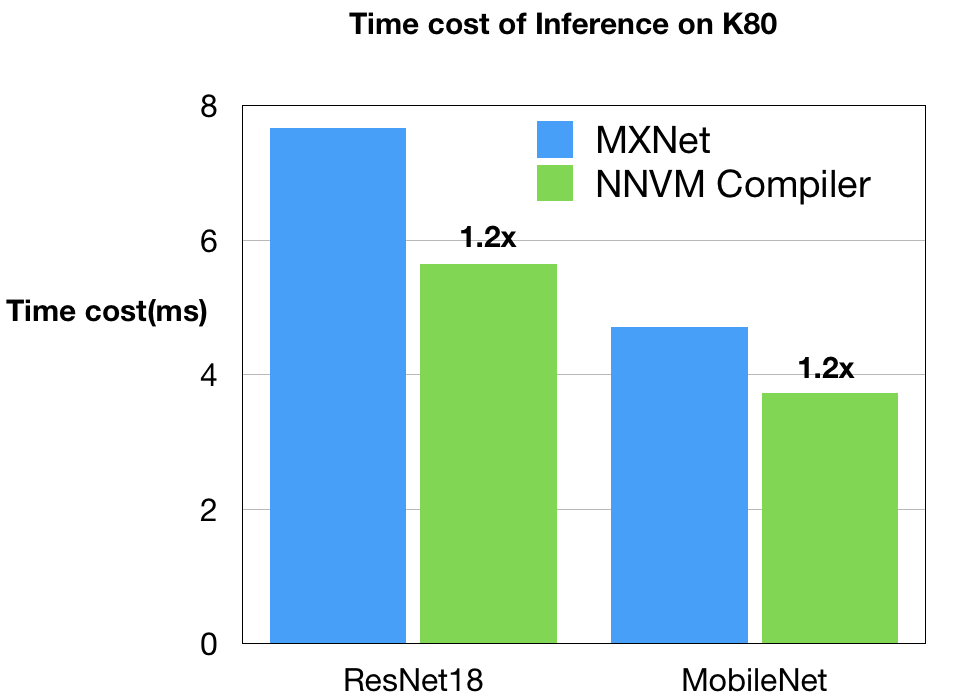
As can be seen, NNVM compiler generate code that outperforms Apache MXNet on K80. These improvements are due to the joint graph level and kernel level optimizations. It is worth noting that NNVM compiler generates all the optimized GPU kernels on its own without relying on external libraries like CuDNN.
Raspberry Pi 3b
The Rasberry Pi compilation stack is contributed by Ziheng Jiang(AWS/FDU). We compared NNVM compiler against Apache MXNet with OpenBLAS and NNPack. We explored the setups to get the best performance out of MXNet: we turned on Winograd convolution in the NNPACK for 3x3 convolutions, enabled multi-threading and disabled the additional scheduler thread (so all threads are used by NNPack).
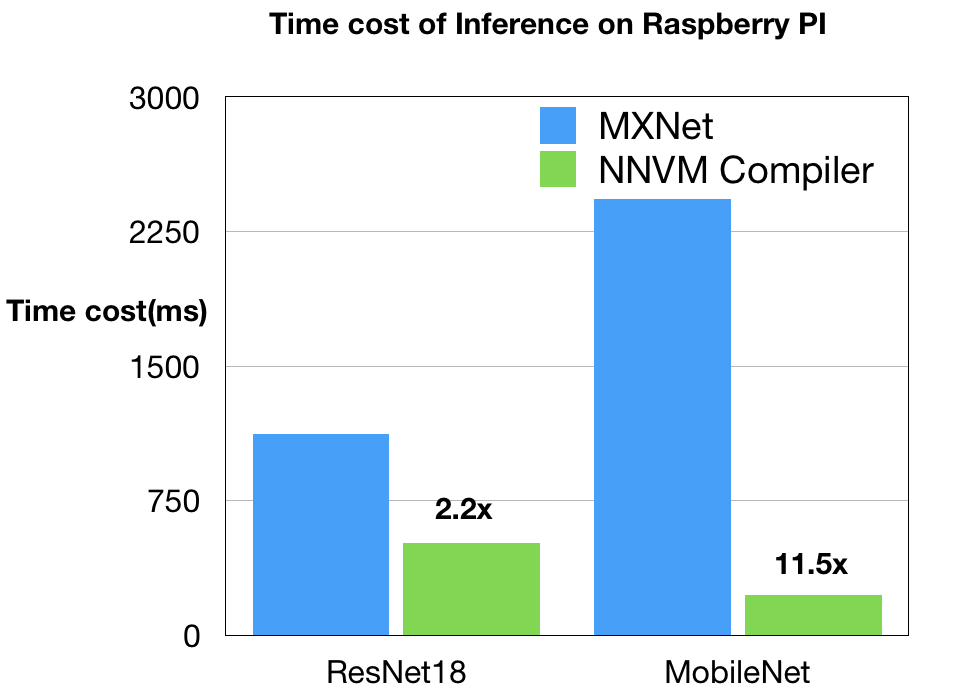
As can be seen, the code generated by NNVM compiler is two times faster on ResNet18. The gap on MobileNet is mainly due to lack of depthwise convolution in existing CPU DNN libraries. NNVM compiler takes benefit of direct generating efficient ARM code directly.
Acknowledgement
This project wouldn’t become possible without our early contributors in the DMLC community. We would like to specially thank Yuwei Hu(TuSimple), Leyuan Wang(AWS/UCDavis), Joshua Z. Zhang(AWS) and Xingjian Shi(HKUST) for their early contributions to the project. We would also like to thank all the contributors to the TVM stack.
We also learnt a lot from the following projects when building NNVM Compiler.
- Theano: possibly the earliest compiler for deep learning
- Halide: TVM uses HalideIR as data structure for arithematic simplification and low level lowering. HalideIR is derived from Halide. We also learns from Halide when implementing the lowering pipeline in TVM.
- Loopy: use of integer set analysis and its loop transformation primitives.
Links
- Github page of NNVM Compiler: https://github.com/dmlc/nnvm
- Github page of TVM: https://github.com/dmlc/tvm
- UW Allen school blog about NNVM compiler
- AWS blogpost about NNVM compiler