In this post, we describe the Bring Your Own Datatypes framework, which enables the use of custom datatypes within TVM.
Introduction
When designing accelerators, an important decision is how one will approximately represent real numbers in hardware.
This problem has had a longstanding, industry-standard solution: the IEEE 754 floating-point standard.1
Yet,
when trying to squeeze
the most out of hardware
by building highly specialized designs,
does it make sense to use
general-purpose IEEE 754 floats?
If we know the numerical requirements
of our workload,
could we build a smaller,
faster,
or more power efficient datatype?
The answer is yes!
Researchers have already begun experimenting with new datatypes in academic and industrial accelerator designs.
For example, Google’s Tensor Processing Unit (the TPU) uses the bfloat type: a single-precision IEEE float which has been truncated to 16 bits.
Due to the lax numerical requirements
of many deep learning workloads,
this truncation often has no effect
on model accuracy,
while instantly cutting the storage cost
in half.23
Before researchers begin building hardware for their datatype, however, they first need to determine how their datatype will behave numerically in the workloads they care about. This often involves first building a software-emulated version of their datatype (e.g. Berkeley SoftFloat or libposit), and then hacking the datatype directly into workloads, to see how the workload performs using the datatype. Even better is to integrate the datatype directly into compilers themselves, so that many different workloads can be compiled to use the datatype. Both routes can be tedious, with the latter route often becoming unmanageable given the size and complexity of modern compilers. One example taken from GitHub shows someone hacking the posit datatype into TensorFlow. The result is 237 commits, adding nearly 6000 lines of code and touching over 200 files across the codebase—and that’s just to add one datatype! This amount of work is prohibitive for many researchers.
To address these problems, we present the Bring Your Own Datatypes framework. The framework enables easy exploration of new datatypes in deep learning workloads by allowing users to plug their simulated datatype into TVM. Unlike the posits-in-Tensorflow example above, which enables a single new datatype in a compiler, the Bring Your Own Datatype framework enables a huge variety of user-defined types.
Bring Your Own Datatypes
The goal of the Bring Your Own Datatypes framework
is to enable users to run deep learning workloads
using custom datatypes.
In the Bring Your Own Datatypes framework,
“datatype” means a scalar type:
float
or uint, for example.
We do not handle more complicated data formats
such as block floating point
or Intel’s Flexpoint.
Additionally,
we only claim to support
software emulated versions of these scalar datatypes;
we do not explicitly support compiling and running on custom datatype hardware.
Each tensor in TVM
is assigned a type code,
which defines the datatype of the scalars
within the tensor.
A number of these type codes
have hard-coded meanings in TVM,
mapping to common datatypes
such as int and float.
However,
the vast majority of type codes
are unused.
The Bring Your Own Datatypes framework
allows users to
claim these unused type codes
and add their own new datatypes
at runtime.
The framework is implemented as a registry which sits alongside TVM’s normal datatype facilities. There are two primary ways in which the user interacts with the datatype registry: first, datatype registration, and second, lowering function registration. These steps are akin to declaration and implementation of the datatype, respectively.
Please note that all referred code in this post are based on TVM repository’s master branch commit 4cad71d. We will use an example posit datatype which can be found under src/target/datatype/posit/posit-wrapper.cc and can be compiled in TVM with the USE_BYODT_POSIT flag.4
Datatype Registration
To register the datatype, the user assigns the datatype a name and a type code, where the type code comes from the range of unused type codes available to custom datatypes.
tvm.target.datatype.register('posit', 150)
The above code registers
the 'posit' datatype
with type code 150.
This registration step
allows TVM to parse programs
which use the custom type:
x = relay.var('x', shape=(3, ), dtype='float32')
y = relay.var('y', shape=(3, ), dtype='float32')
x_posit = relay.cast(x, dtype='custom[posit]16')
y_posit = relay.cast(y, dtype='custom[posit]16')
z_posit = x_posit + y_posit
z = relay.cast(z_posit, dtype='float32')
program = relay.Function([x, y], z)
print(program)
# v0.0.4
# fn (%x: Tensor[(3), float32], %y: Tensor[(3), float32]) {
# %0 = cast(%x, dtype="custom[posit]16");
# %1 = cast(%y, dtype="custom[posit]16");
# %2 = add(%0, %1);
# cast(%2, dtype="float32")
# }
The program above
casts float32 inputs x and y
into posits,
adds them,
and casts the result back to float32.
Once the posit type is registered,
TVM is able to parse the special dtype syntax
custom[<typename>],
where <typename> is the name registered for the type.
This syntax also supports the usual
<bits>x<lanes> format;
here, we use 16 to indicate that
each posit is 16 bits wide.
(The number of lanes
defaults to 1.)
Lowering Function Registration
Though TVM can parse the above program,
it cannot yet compile it,
as TVM does not yet understand
how to compile operations
over the posit type.
To compile these programs,
we register lowering functions for the custom datatype,
which help TVM convert the operations
into something it can understand and compile.
Generally, the user is not expected to lower operations directly to LLVM or CUDA. Instead, most code using custom datatypes can be lowered into code which doesn’t use custom datatypes, with some simple tricks. We can then rely on native TVM to understand and compile the code.
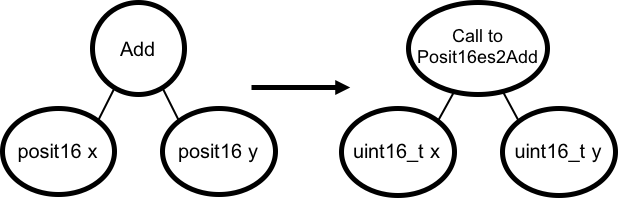
Figure 1 shows a common pattern.
Let’s assume we are
interested in exploring the posit type,
and have chosen to run some workloads
by plugging a posit emulation library (e.g. Stillwater Universal) into TVM
via the Bring Your Own Datatypes framework.
Our workload is a simple program
which adds two posit inputs.
Native TVM does not understand
how to implement posit addition—but it doesn’t need to,
as we have a library implementing our datatype!
The library contains an implementation of posit addition,
alongside other operators such as multiplication and square root.
To implement this posit addition,
we’d just like to call into our library.
Thus, our Add node should become a Call node,
calling out to a function (call it Posit16es2Add) in our library.
To store the bits of the input posits
inside a type that TVM understands,
we use 16-bit unsigned integers.
The resulting program
is one that TVM can understand and compile—it
is simply a call to an external library function,
taking two unsigned integers.
To achieve the above lowering,
we register a lowering function
for posit:
tvm.target.datatype.register_op(
tvm.target.datatype.create_lower_func({16: 'Posit16es2Add'}),
'Add', 'llvm', 'posit')
The above code registers
a lowering function
for a specific operator (Add),
compilation target (LLVM),
datatype (posit), and bit length (16).
The first argument
is the lowering function.
This can be any function
taking a TVM IR node
and returning a new TVM IR node.
In our case,
we use a helper function
provided by the Bring Your Own Datatypes framework.
tvm.target.datatype.create_lower_func({16:'Posit16es2Add'})
creates a lowering function
for the common pattern described above.
The resulting function
converts the arguments of the given node
to uint16_t,
and then converts the node itself
into a call to the given function name
(in this case, 'Posit16es2Add' for posits of bit length 16).
We pass a dictionary to create_lower_func so that TVM can dispatch
to the appropriate function name based on the bit length of the datatype.
To implement a custom datatype, the user will need to register a lowering function for every operator in the workload they would like to run. For a network like ResNet, this will be around 10 operators, including things like, Add, Div, various Casts, and Max. In our tests, registering a datatype and all lowering functions takes around 40 lines of Python. Once all needed operators are registered, custom datatype workloads can be run as easily as any other TVM program!
Wrapping Up
The Bring Your Own Datatypes framework brings user-defined datatypes to TVM. We hope this will encourage datatype researchers to use TVM in their research; similarly, we hope this will spark interest in custom datatypes within the deep learning community. For more documentation about the Bring Your Own Datatypes framework please visit the Bring Your Own Datatypes to TVM developer tutorial.
Gus Smith is a PhD student at the University of Washington working with Luis Ceze and Zachary Tatlock at the intersection of computer architecture and programming languages. His website is justg.us.
Andrew Liu is an undergraduate student at the University of Washington and a member of UW CSE SAMPL and PLSE labs.
References
-
Jouppi, Norman P., et al. “In-datacenter performance analysis of a tensor processing unit.” Proceedings of the 44th Annual International Symposium on Computer Architecture. 2017. ↩