Apache TVM Unity is a roadmap for the TVM ecosystem in 2022. We see a broader shift coming in the way that machine learning system stacks optimize for flexibility and agility in the face of a rapidly changing hardware landscape. TVM will evolve to break down the boundaries that constrain the ways current ML systems adapt to rapid changes in ML models and the accelerators that implement them.
Boundaries in the Modern ML System Stack
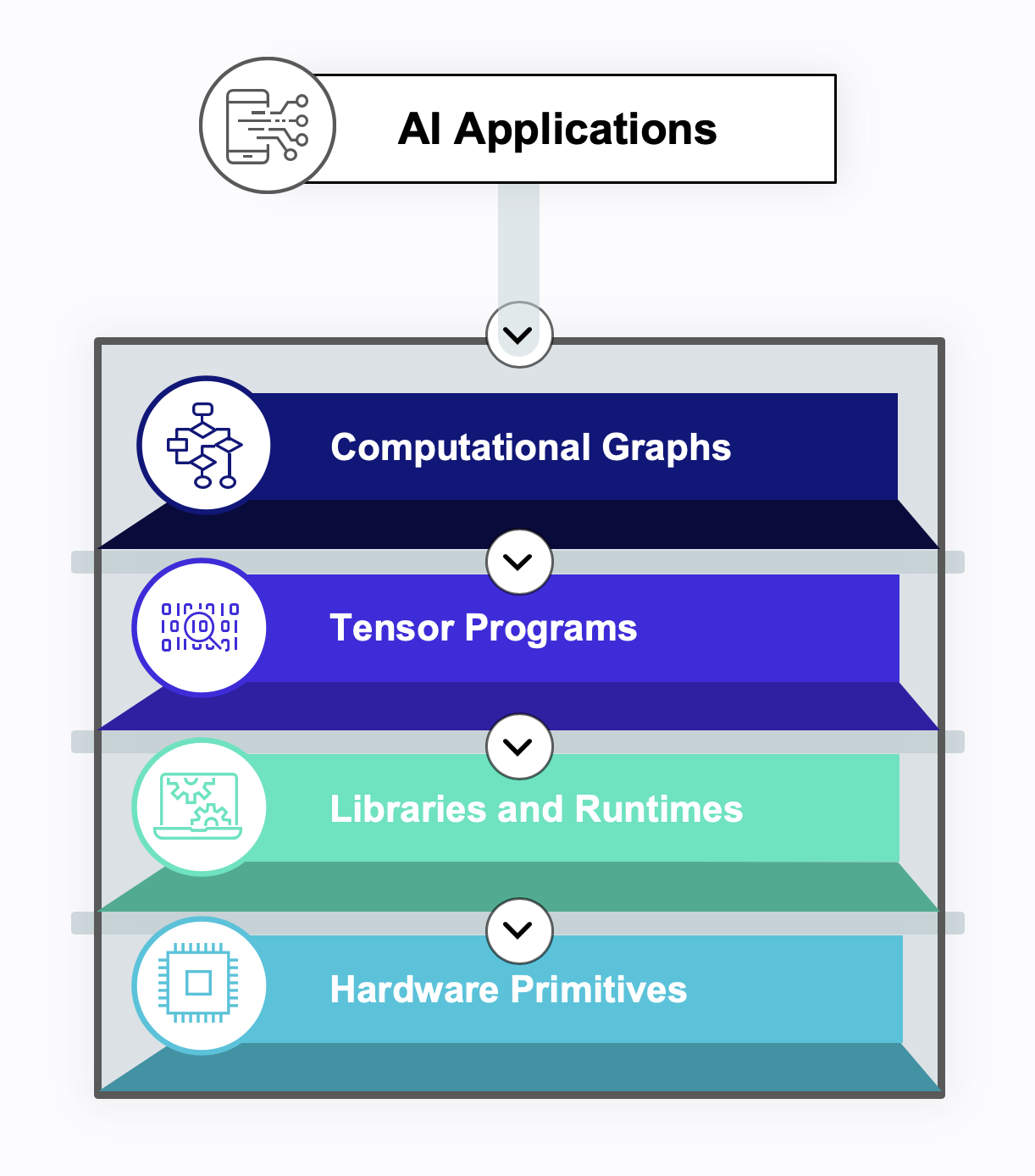
The system stack for modern machine learning consists of four kinds of abstractions:
- The computational graph abstraction encodes the flow of data between coarse-grained tensor operators. Computational graphs are the high-level abstraction users interact with in TensorFlow, MXNet, and PyTorch.
- Tensor programs implement the code for the operators in the computational graph. Deep learning compilers generate the low-level C++ or CUDA code for computations like convolutions or matrix multiplications.
- Similarly, libraries and runtimes include pre-written code to execute and orchestrate tensor operations. BLAS packages and libraries like cuDNN provide extensively tuned operator implementations for specific hardware targets.
- Hardware primitives are at the bottom of the stack. Here, low-level assembly languages and hardware accelerator interfaces expose the raw capabilities of the machine.
There are vertical boundaries between the abstraction levels that prohibit cross-layer interactions and feedback between the levels. There is also a horizontal boundary between two opposing ways that software stacks can treat the central tensor computation level. The horizontal boundary divides library-based and compilation-based approaches to tensor computation.
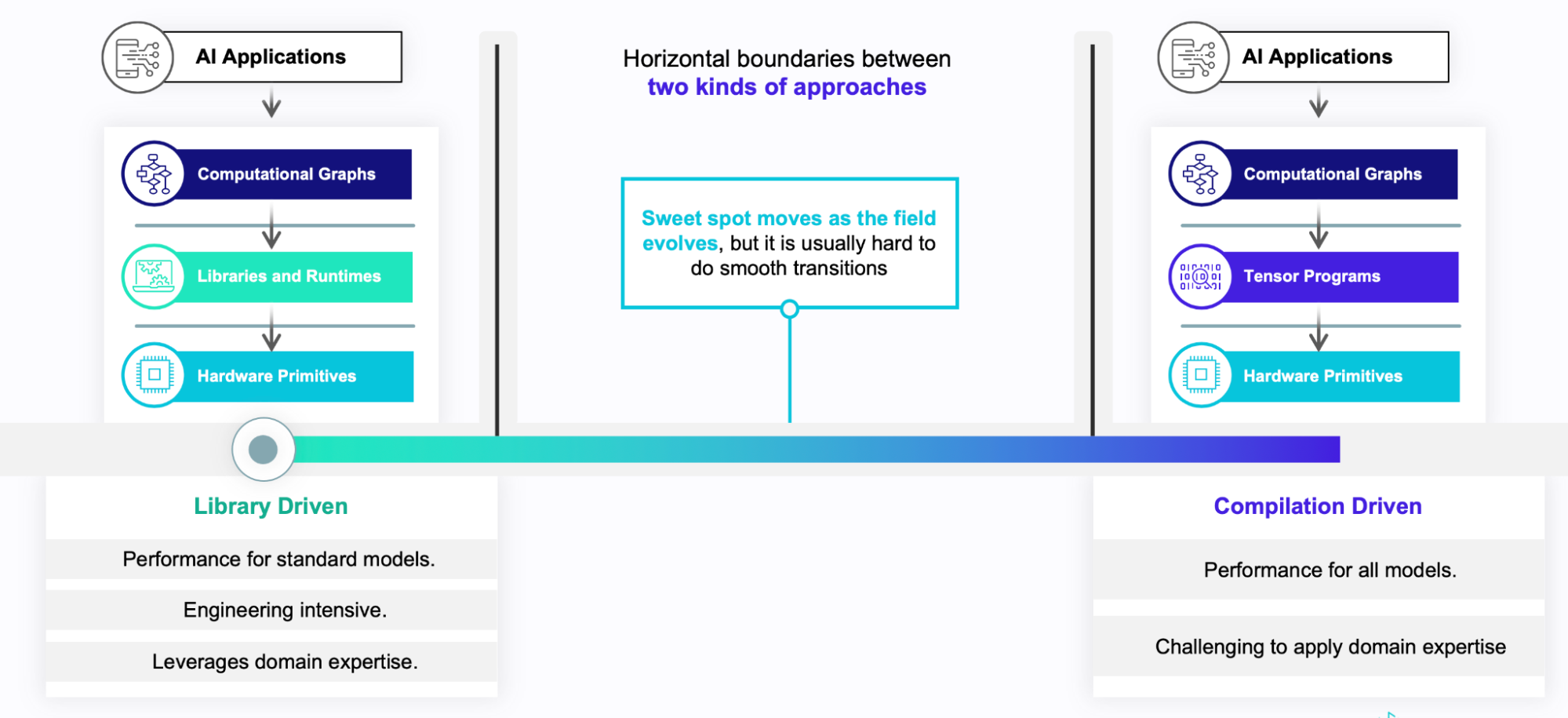
Library-based frameworks rely on collections of pre-made, carefully tuned operator implementations as their computational workhorse. Compilation-based frameworks instead generate their own custom tensor operation code from scratch. Modern software stacks typically use one style or the other, but they don’t combine them: most deep learning frameworks are library-based, while most deep learning compilers cannot incorporate libraries and runtimes.
In the current landscape of ML systems, the boundaries between these layers tend to be strict. Neither approach is better than the other, but they have trade-offs. Library-based stacks excel on standard styles of ML models because they benefit from years of engineering investment common operators. On the other side, the flexibility and automation in compilation-based frameworks can be better for emerging models that require new operators.
Vertical boundaries exist in both styles of software stack. AI applications start at the top of the stack and march through the layers from top to bottom. Frameworks choose data layout and operator fusion strategies at the graph level; then the tensor computations carry out the operators selected in the computational graph; and these operators map onto a fixed set of hardware primitives. It’s a one-shot, unidirectional workflow: performance constraints at the level of tensor programs, for example, cannot feed back to influence the data layout at the computational graph level. And incorporating custom hardware typically means manually propagating new features through all three layers.
Both vertical and horizontal boundaries are slowing down the pace of innovation in machine learning. New hardware accelerators are emerging with new levels of capability and performance, but harnessing them will require fluid collaboration between ML scientists, ML engineers, hardware vendors that these boundaries prevent. To cope with the rapid pace of change in ML systems, frameworks need to support incremental evolution: Incorporating new capabilities should require effort proportional to the change, not wholesale re-engineering at each level.
TVM Unity
The TVM Unity vision is about breaking down these barriers. The goal is to enable cross-layer interactions and automate their optimization. It is not to collapse the abstraction layers into a monolith: there is no “silver bullet” representation for AI programs that simultaneously enables optimization at every level. Instead, TVM Unity will build interfaces for the abstractions to interact and exchange information.
Removing the strict barriers between the levels in the system stack will enable new kinds of optimization that work jointly across the layers. A unified view of the entire system will let TVM automatically co-optimize decisions in the computation graph, the tensor operators, and the hardware mapping to search for the best possible implementation of an AI application. At the same time, TVM Unity will also serve as a communication substrate for interactions between ML scientists, ML engineers, and hardware engineers. This collaboration will be crucial for adapting to the rapid changes that are coming in the next phase of hardware acceleration for ML.
Unifying Abstractions

TVM Unity will focus on letting AI applications fluidly cross the boundaries between operator graphs, tensor programs, and hardware primitives. In TVM, a single Python program can define a core tensor operation, incorporate a custom hardware primitive, and invoke the operation from a larger operator graph. This example shows all of these capabilities:
import tvm.script
from tvm.script import tir as T, relax as R
@tvm.script.ir_module
class MyIRModule:
# Define a TIR based operation.
@T.prim_func
def tir_mm(X: T.Buffer[(n, d), "float32"],
W: T.Buffer[(d, m), "float32"],
Y: T.Buffer[(n, m), "float32"]):
for i, j, k in T.grid(n, m, d):
with T.block("body"):
vi, vj, vk = T.axis.remap("SSR", [i, j, k])
with T.init():
Y[vi, vj] = 0
# Can be mapped on to HW intrinsics.
Y[vi, vj] += X[vi, vk] * W[vk, wj]
@R.function
def relax_func(x: R.Tensor[(n, d), "float32"], w: R.Tensor[(d, m), "float32"]):
with R.dataflow()
# Invoke the TIR code.
lv0: R.Tensor[(n, m), "float32"] = R.call_dps((n, m), tir_mm, [x, w])
lv1: R.Tensor[(n * m,), "float32"] = R.flatten(lv0)
gv0: R.Tensor[lv2, "float32"] = R.exp(lv1)
R.output(gv0)
# Invoke external update rule.
R.call_packed("custom_inplace_update", gv0)
return gv0
This code has both a tensor program (tir_mm) and computational graph that includes it (relax_func). The high-level data flow can directly invoke the low-level tensor manipulation to build up a larger computation. The TVM runtime unifies the operator graph and compiler-based tensor computation to optimize the entire program. This code also uses call_packed to invoke a pre-baked operator—showing how TVM can smoothly integrate library-based operators with the custom computation.
Additionally, TensorIR opens doors to exploit hardware primitives through tensorization. Tensorization transforms loop-level programs to implementations that map onto the primitives that a particular hardware target declares.
The key to highlight here is cross layer interactions. Our particular example shows interactions between: (1) computational graph and tensor programs; (2) computational graph and runtime libraries; (3) Finally tensor programs and hardware primitives through on-going automatic tensorization developments in TensorIR. These cross layer interactions open doors for making incremental optimizations at the boundary. For example, we can build a customized pass to the lower part of the subgraph to a set of runtime libraries then pass on to the rest of the pipeline.
In addition to the unification of abstraction layers, we are also working on unifying the shape representation, to enable first class symbolic shape support across the stack. In our particular example, the symbolic shape dimensions(n, m) can flow across the abstractions and enable advanced optimizations for dynamic workloads. The additional capabilities will open doors for both training and inference workload optimizations.
Unifying Perspectives
Better ML systems require collaboration between ML scientists, ML engineers, and hardware engineers. The coming era of diverse specialized ML hardware will require coordinated effort from teams that include all three groups. By building rich, bidirectional interfaces between the layers in the system stack, TVM Unity aims to be the medium through which this collaboration and iteration happens.
Abstractions in TVM can catalyze the lifecycle of an improvement to an AI application. At the highest level, an ML scientist can specify the operator they need to construct the next generation of a model. ML engineers can work at the tensor computation level to make this new operation efficient. Finally, these tensor computations can rely on hardware primitives written by hardware engineers. The work at each level will interact through Python APIs within the TVM ecosystem. The ability to work together within TVM, rather than invasively modifying a framework with each new feature, will be the key to fast iteration in the face of rapidly evolving hardware.
Automation
A unified ML system creates a new, larger search space than a system stack with strict boundaries. Decisions within tensor computations can influence the structure of the operator graph, and new hardware primitives can drastically change the optimal mappings at every other layer.
TVM Unity will expose all these cross-layer interactions for automated optimization. Finding the best implementation for a given application will require learning-driven optimization: using ML to optimize ML by exploring the expanded joint search space and minimize the computational cost.
In addition to that, we also want to leverage domain experts’ help when possible, and create mechanisms to effectively incorporate domain information to help guide the automatic optimizations.
New Capabilities with Unity
The Unity vision guides the technical roadmap for TVM’s evolution over the next year. The unified approach will position TVM to offer new forms of automation and ecosystem integration that are not possible with today’s system stacks.
With Unity, TVM will unify library-based computation with compiler-based automation. AI applications will be able to combine the world’s best known code for common operators with automatically optimized code for computations that don’t map neatly onto any existing operator. Developers will be able to smoothly transition between both strategies without a steep “performance cliff” when switching from built-in to generated code. Teams will be able to iterate rapidly with compiled code for new model designs and then, as models mature and stabilize, fluidly incorporate optimized operator libraries to maximize performance. By erasing the boundary between operator-based and compiler-based stacks, TVM will enable automatic exploration of the trade-off space between the two extremes.
TVM also aims to serve as a bridge to unify the broader ML and hardware ecosystems. In the ML ecosystem, TVM offers a minimal runtime that does not constrain teams’ choice of frameworks. TVM models will be easy to embed into other frameworks and runtimes as subgraphs for both training and inference. Through exchange formats like ONNX and TorchScript, TVM models can fluidly integrate into larger applications built on any infrastructure. In the hardware ecosystem, TVM is already the best way for accelerator designers to integrate with ML applications. With TVM Unity, hardware vendors will easily onboard into TVM via a simple set of operators and then incrementally transition to compilation-based integration for better flexibility. This way, new hardware capabilities can get started improving AI applications without reinventing the whole system stack.
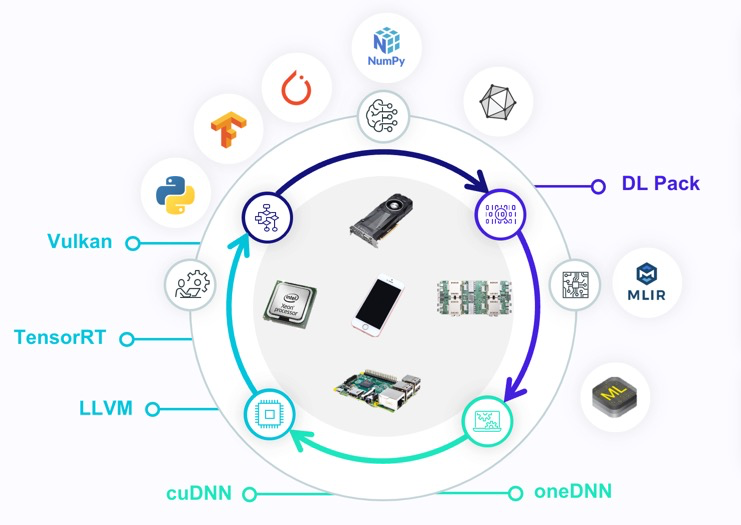
Beyond TVM alone, the same forces that are driving TVM Unity exist across the theory and practice of modern ML. Rapid changes to models, emerging alternative hardware, and aging abstraction boundaries all point toward the need for an integrated approach. We expect TVM to lead the way into the next great industry-wide shift in ML systems.
For more details about our vision for TVM, check out TVMCon 2021 for more talks and discussion.