We are currently living in an exciting era for AI, where machine learning systems and infrastructures are crucial for training and deploying efficient AI models. The modern machine learning systems landscape comes rich with diverse components, including popular ML frameworks and array libraries like JAX, PyTorch, and CuPy. It also includes specialized libraries such as FlashAttention, FlashInfer and cuDNN. Furthermore, there’s a growing trend of ML compilers and domain-specific languages (DSLs) operating at both graph and kernel levels, encompassing tools like Torch Inductor, OpenAI Triton, TileLang, Mojo, cuteDSL, Helion, Hidet and more. Finally, we are starting to see intriguing developments of coding agents that can generate kernels and integrate them into ML systems.
The exciting growth of the ecosystem is the reason for today’s fast pace of innovation in AI. However, it also presents a significant challenge: interoperability. Many of those components need to integrate with each other. For example, libraries such as FlashInfer and cuDNN need to be integrated into PyTorch, JAX, and TensorRT’s runtime system, each of which may come with different interface requirements. ML compilers and DSLs also usually expose Python JIT binding support, while also needing to bring separate ahead-of-time compilation to specific exposure to non-Python environments such as automotive and mobile. The emergence of coding agents makes it even more interesting, as each agent is its own mini code generator that needs to interface with various deployment scenarios. As of now, the ecosystems address these challenges by creating numerous specific bindings for each DSL and library to deployment environments (Python/Torch/JAX/TensorRT, etc.).
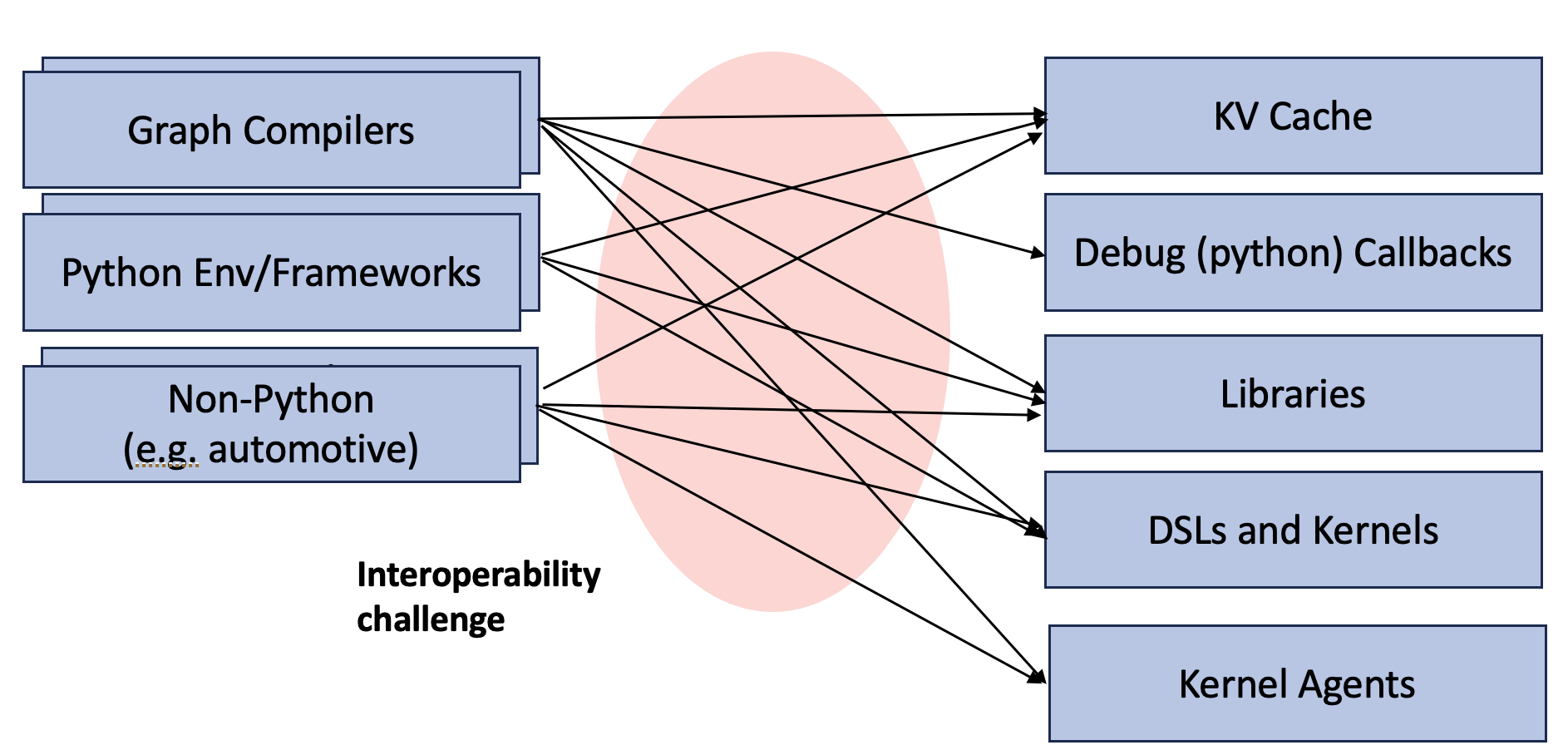
At the core of these interoperability challenges are the Application Binary Interface (ABI) and the Foreign Function Interface (FFI). ABI defines how data structures are stored in memory and precisely what occurs when a function is called. For instance, the way PyTorch stores Tensors may be different from CuPy/NumPy, so we cannot directly pass a torch.Tensor pointer and treat it as a cupy.NDArray. The very nature of machine learning applications usually mandates cross-language interop (one specific example is Python and extensions). Each ML compiler DSL can be viewed as its own language requiring runtime bindings to Python and other deployment environments. As the ML system ecosystem thrives and each DSL component excels at its particular focus and complements others, bringing FFI as a first-class citizen would be extremely valuable.
All of the above observations call for a need for ABI and FFI for ML systems use cases. Looking at the current state, luckily, we do have something to start with – the C ABI, which every programming language speaks and remains stable over time. Unfortunately, C only focuses on low-level data types such as int, float and raw pointers. On the other end of the spectrum, we know that Python is something that must gain first-class support, but there is still a need for different-language deployment for scenarios like automotive and mobile. While it may sound ambitious for all kinds of languages, DSLs, and runtimes to work together, there is some hope, because we are focusing on a specialized domain – machine learning. We know that the key data structures and values being passed around are primarily Tensors sitting on GPUs. We can take a minimalist approach by focusing on ML cases and building portable ways to exchange GPU Tensors and functions that operate on these data structures.
This post introduces TVM FFI, an open ABI and FFI for machine learning systems. The project evolved from multiple years of ABI calling conventions design iterations in the Apache TVM project. We find that the design can be made generic, independent of the choice of compiler/language and should benefit the ML systems community. As a result, we built a minimal library from the ground up with a clear intention to become an open, standalone library that can be shared and evolved together by the machine learning systems community. It also draws collective wisdom from the ML System community, including past development insights from many developers from NumPy, PyTorch, JAX, Caffe, MXNet, XGBoost, CuPy and more. It contains the following key elements:
- Stable, minimal C ABI designed for kernels, DSLs, and runtime extensibility.
- Zero-copy interop across PyTorch, JAX, and CuPy using DLPack protocol.
- Compact value and call convention covering common data types for ultra low-overhead ML applications.
- Multi-language support out of the box: Python, C++, and Rust (with a path towards more languages).
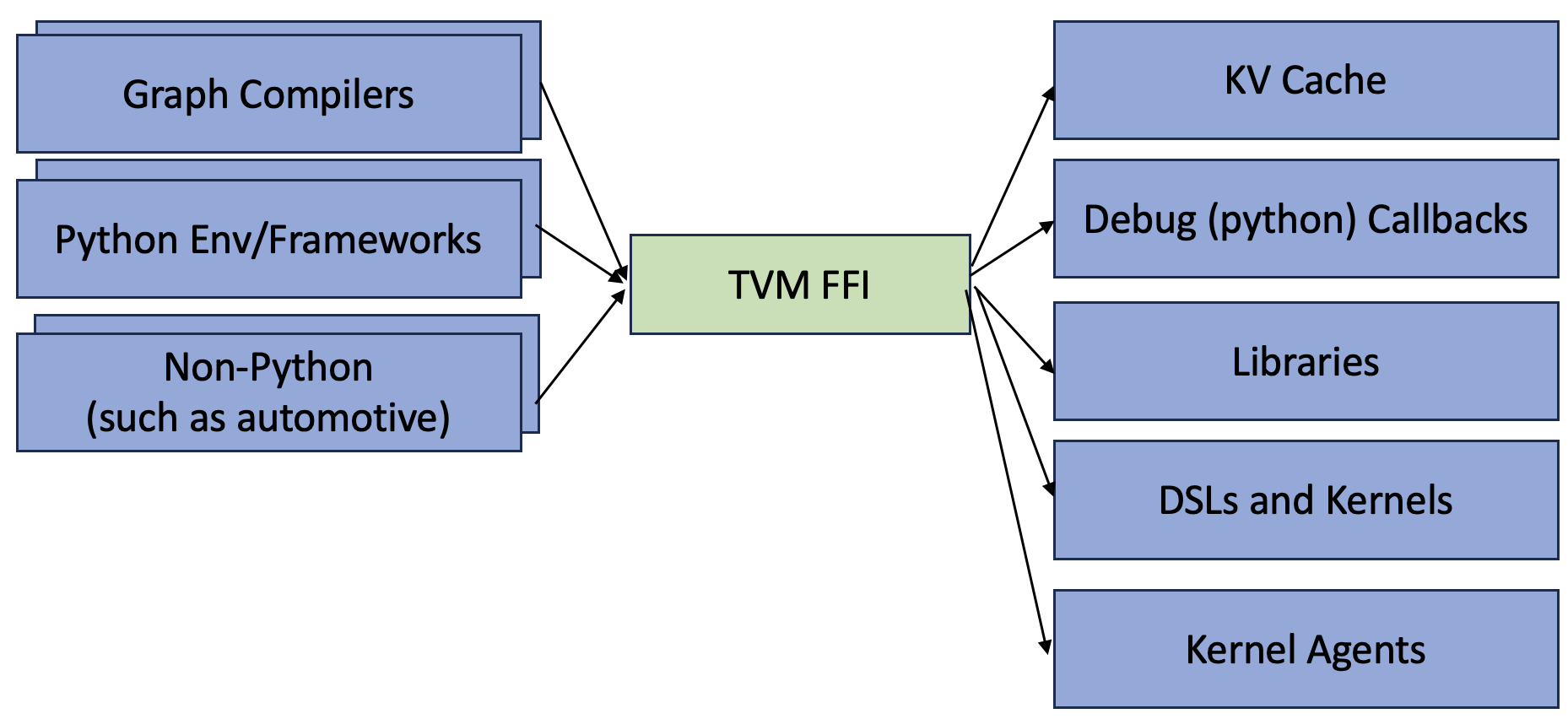
Importantly, the goal of the project is not to create another framework or language. Instead it aims to get the ML system components to do their magic, and enables them to amplify each other more organically.
Technical Design
To start with, we need a mechanism to store the values that are passed across machine learning frameworks. It achieves this using a core data structure called TVMFFIAny. It is a 16-byte C structure that follows the design principle of tagged union
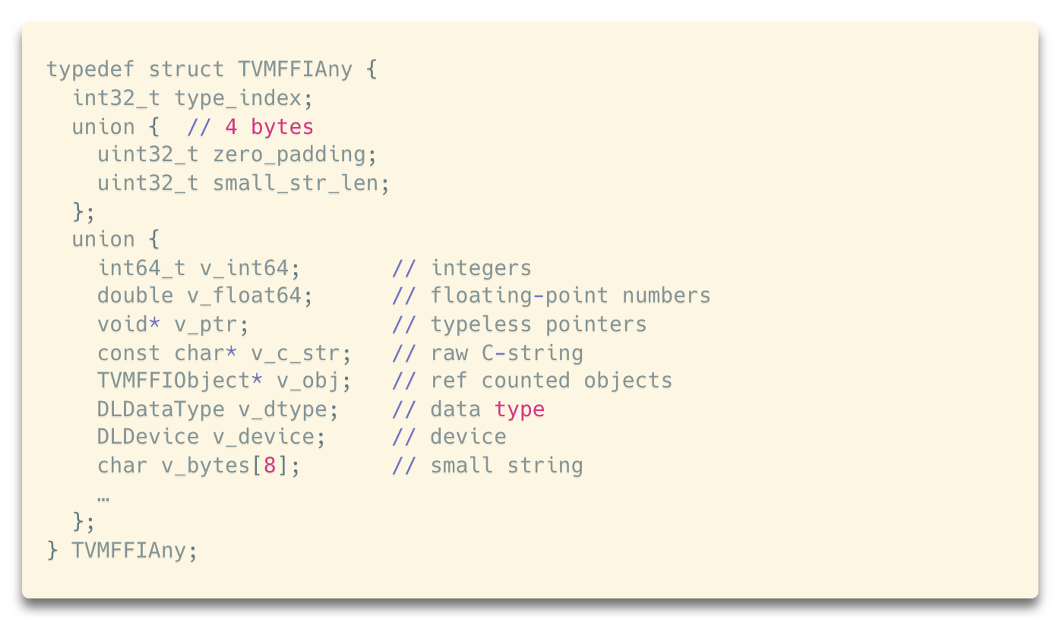
The objects in TVMFFIObject are managed as intrusive pointers, where TVMFFIObject itself contains the header of the pointer that helps manage type information and deletion. This design allows us to use the same type_index mechanism that allows for future growth and recognition of new kinds of objects within the FFI, ensuring extensibility. The standalone deleter ensures objects can be safely allocated by one source or language and deleted in another place.

We provide first-class support for owned and unowned Tensor support that adopts DLPack DLTensor layout. Thanks to the collective efforts from the ML system ecosystems, we can leverage DLPack for first class support and bring in tensors/arrays from PyTorch, NumPy, JAX. We also provide support for common data types such as string, array, and map. Generally, these values cover most common machine learning system use cases we know of. The type_index mechanism still leaves room for registering objects with dynamic type index at runtime based on a string type key, enabling us to bring in more object types if needed.
As discussed in the overview, we need to consider foreign function calls as first class citizens. We adopt a single standard C function as follows:

The handle contains the pointer to the function object itself, allowing us to support closures. args and num_args describe the input arguments and results store the return value. When args and results contain heap-managed objects, we expect the caller to own args and results.
We call this approach a packed function, as it provides a single signature to represent all functions in a “type-erased” way. It saves the need to declare and JIT shim for each FFI function call while maintaining reasonable efficiency. This mechanism enables the following scenarios
- Calling from Dynamic Languages (e.g., Python): we provide a tvm_ffi binding that prepares the args based on dynamically examining Python arguments passed in.
- Calling from Static Languages (e.g., C++): For static languages, we can leverage C++ templates to directly instantiate the arguments on the stack, saving the need for dynamic examination
- Dynamic language Callbacks: the signature enables us to easily bring dynamic language (Python) callbacks as ffi::Function, as we can take each argument and convert to the dynamic values.
Efficiency In practice, we find this approach is sufficient for machine learning focused workloads. For example, we can get to 0.4 us level overhead for Python/C++ calls, which is already very close to the limit (for reference, each python c extension call is at least 0.1us), and much faster than most ML system python eager use cases which are usually above 1-2 us level. When both sides of calls are static languages, the overhead will go down to tens of nanoseconds. As a side note, although we did not find it is necessary, the signature still leaves room for link time optimization (LTO), when both sides are static languages with a known symbol and linked into a single binary when we inline the callee into caller side and the stack argument memory passing into register passing.
We support first class Function objects that allow us to also pass function/closures from different places around, enabling cool usages such as quick python callback for prototyping, and dynamic Functor creation for driver-based kernel launching.
Error handling Because the function ABI is based on C, we need a method to propagate errors. A non-zero return value of TVMFFISafeCallType indicates an error. We provide a thread-local storage (TLS) based C API to set and fetch errors, and we also build library bindings to automatically translate exceptions. For example, the macro
will raise an exception that translates into a TypeError in Python. We also preserve and propagate tracebacks across FFI boundaries whenever possible. The TLS-based API is a simple yet effective convention for DSL compilers and libraries to leverage for efficient error propagation.
First-class GPU Support for PyTorch We provide first-class support for torch.Tensors, it will automatically zero-copy transfer to an FFI Tensor. We also provide a minimal stream context so that the stream is carried over from the PyTorch Stream context. In short, calling a function would serve like a normal PyTorch functions when passing in torch Tensor arguments.
Ship One Wheel
TVM FFI provides a minimal pip package that includes libtvm_ffi, which handles essential registration and context management. The package consists of a C++ library that automatically manages function types built upon the C ABI, and a Python library for interacting with this convention. Because we defined a stable ABI for ML systems, kernel libraries, the compiled library is agnostic to Python ABI and PyTorch versions, and can work across multiple python versions (including free-threaded python). This allows us to ship one wheel(library) for multiple frameworks and python environments, and greatly simplifies the deployment.
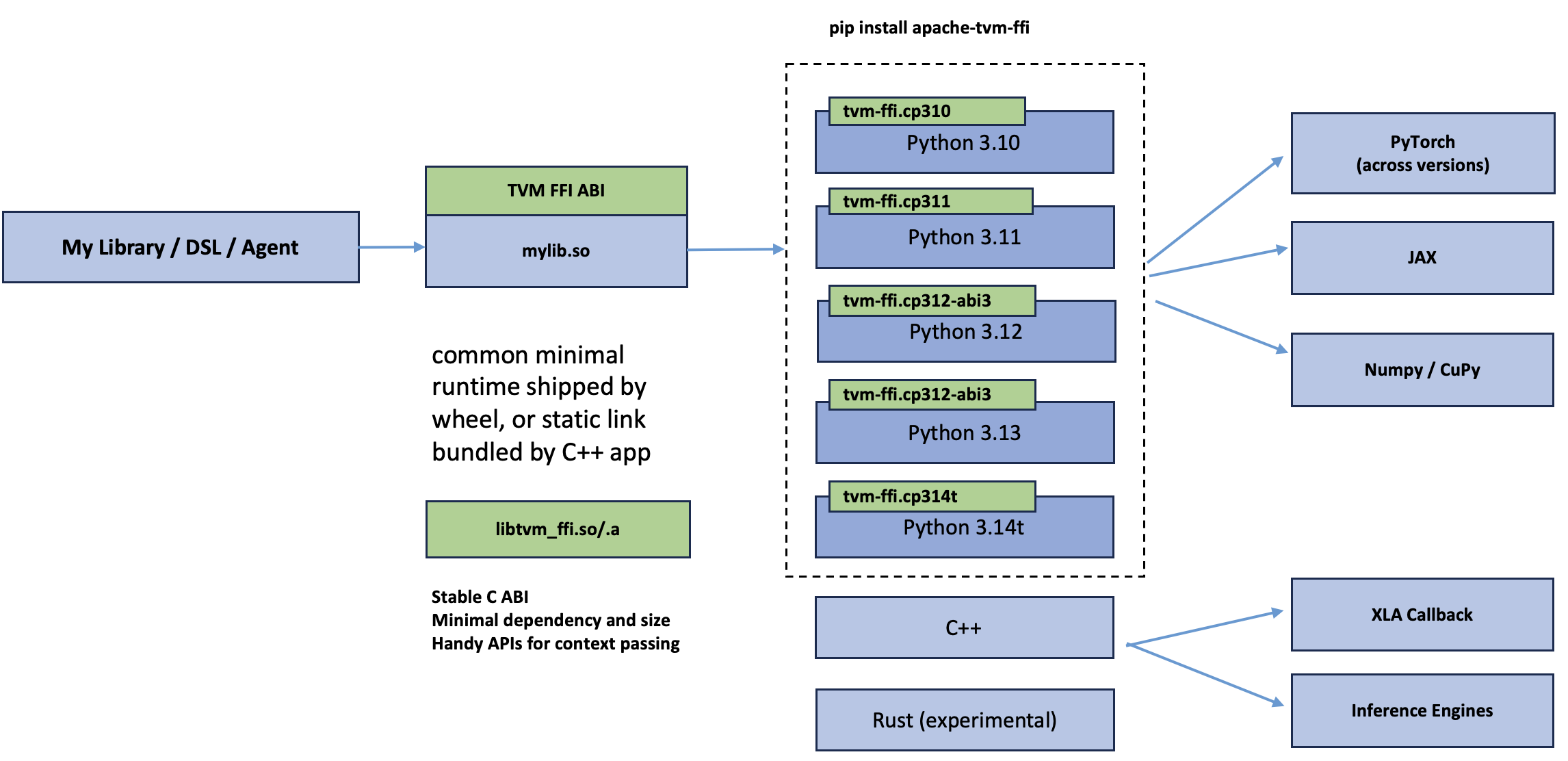
The above figure shows how it works in practice, most libraries only need to ship mylib.so that links to the ABI, then the particular python version specific apache-tvm-ffi package will handle the bridge to specific Python version. The same mechanism also works for non-python inference engines. There are many ways to build a library that targets the tvm-ffi ABI. The following example shows how can we do that in cuda

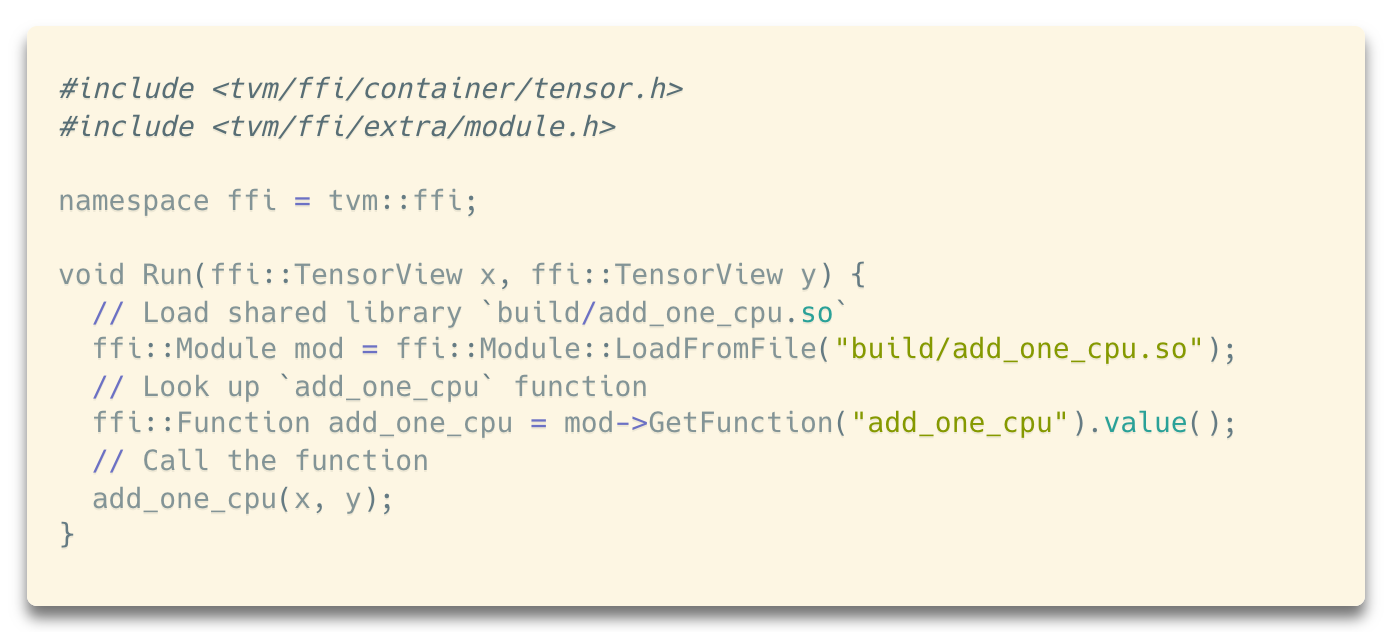
Once we compiled this library into mylib, then it can be loaded back into Python or any other runtime that works with TVM FFI.

Notably, this same function can be loaded from other runtimes and languages that interfaces with the tvm-ffi. For example, the same example contains a C++ loading
The ABI is designed with the needs of DSL compilers in mind. Because the ABI is minimal, we can readily target it in C (or any of low-level compiler IRs such as LLVM IR, or MLIR LLVM dialect). Once DSL integrates with the ABI, we can leverage the same flow to load back and run the library as normal torch functions. Additionally, we can also support JIT mechanisms to the same ABI.

Core Design Principle and Applications
Coming back to the high level, the core design principle of the TVM FFI ABI is to decouple the ABI design from the binding itself. Most binding generators or connectors focus on point-to-point interop between language A and framework B. By designing a common ABI foundation, we can transform point-to-point interop into a mix-and-match approach, where we can have n languages/frameworks connect to the ABI and then back to another m DSLs/libraries. The most obvious use case is to expose C++ functions to Python; but we can also use the same mechanism to expose C++ functions to Rust; the ABI helps expose WebAssembly/WebGPU to TypeScript in the recent WebLLM project, or expose DSL-generated kernels to these environments. It can also use the ABI as a common runtime foundation for compiler runtime co-design in ML compilers and kernel DSLs. These are just some of the opportunities we may unblock. In summary, the common open ABI foundation offers numerous opportunities for ML systems to interoperate. We anticipate that this solution can significantly benefit various aspects of ML systems and AI infrastructure:
- Kernel libraries: Ship a single package to support multiple frameworks, Python versions, and different languages.
- Kernel DSLs: a reusable ABI for JIT and AOT kernel exposure frameworks and runtimes.
- Frameworks and runtimes: Offer a uniform interop with ABI-compliant libraries and DSLs.
- ML infrastructure: Enable out-of-the-box interoperability for Python, C++, and Rust.
- Coding agents: Establish a unified mechanism for shipping generated code in production.
Currently, the tvm-ffi package offers out-of-the-box support for frameworks like PyTorch, JAX, and CuPy. We are also collaborating with machine learning system builders to develop solutions based on it. For instance, FlashInfer now ships with tvm-ffi, and active work is underway to enable more DSL libraries, agent solutions, and inference runtimes. This project also is an important step for Apache TVM itself, as we will start to provide neutral and modular infrastructure pieces that can be useful broadly to the machine learning system ecosystems.
Links
TVM FFI is an open convention that is independent from a specific compiler or framework. We welcome contributions and encourage the ML systems community to collaborate on improving the open ABI. Please checkout the following resources:
Acknowledgement
The project draws collective wisdoms of the Machine Learning System community and python open source ecosystem, including past development insights of many developers from numpy, PyTorch, JAX, Caffe, mxnet, XGBoost, cuPy, pybind11, nanobind and more.
We would specifically like to thank the PyTorch team, JAX team, CUDA python team, cuteDSL team, cuTile team, Apache TVM community, XGBoost team, TileLang team, Triton distributed team, FlashInfer team, SGLang community, TensorRT-LLM community, the vLLM community, for their their insightful feedbacks.