Today we are introducing TIRx, an open-source, hardware-native DSL and compiler for ML kernels, built on Apache TVM. It targets the part of the AI software stack where fast-moving kernels meet fast-moving hardware: TIRx compiles to GPUs and specialized AI accelerators today and is designed to grow with the generations that follow. The same design serves expert-written kernels, agent-generated kernels, and megakernel systems.
We have been working together with the broader community to provide the following materials at launch:
- PyPI wheel and Python frontend. A Python-embedded hardware-native kernel DSL with
@T.jit/@T.prim_funcstyle authoring, parser utilities, and Python APIs for constructing TIRx programs. - TIRx kernel library and benchmarks. End-to-end examples covering GEMM, attention-style kernels, and low-precision operators on Blackwell GPUs.
- Open course on modern GPU programming. This curated online course was taught as part of the machine learning systems course at Carnegie Mellon University, and uses TIRx to teach students modern GPU programming for machine learning systems.
You can find the following resources:
- GitHub: https://github.com/apache/tvm
- Documentation: https://tvm.apache.org/docs/tirx/overview.html
-
PyPI wheel: https://pypi.org/project/apache-tvm/0.25.0/
pip install apache-tvm - Community TIRx kernel library: https://github.com/mlc-ai/tirx-kernels
- Modern GPU programming for machine learning systems: https://mlc.ai/modern-gpu-programming-for-mlsys/index.html
Motivation
Kernel DSLs are most effective when they choose the right boundary between the programmer and the machine. For mature kernels and mature hardware, that boundary can be high-level: the compiler hides thread assignment, memory movement, layout details, and instruction selection behind compact tensor or tile abstractions. Triton is the canonical example, and its adoption shows how well this works for established kernel patterns. At the frontier, the same boundary is under more pressure. New instructions, memory spaces, cooperation patterns, and kernel algorithms often appear before a compiler has the built-in machinery to automate them well. When that happens, the parts a high-level compiler would normally hide are exactly the parts an expert still needs to control by hand.

TIRx (pronounced “tier-ex”) responds by choosing a lower and more explicit boundary, organized around three decisions:
- Orchestration stays in the hardware-native source. Pipeline structure, synchronization, role assignment, memory placement, and backend intrinsics are the parts that most often need expert control at the frontier, so TIRx keeps them in source rather than behind an abstraction that may not yet model a new feature.
- Recurring tile primitives are exposed to the compiler. Execution scope, tensor layout, and tile primitive dispatch let common operations stay reusable, analyzable, and portable across backends, without forcing the whole kernel through a fixed compiler pipeline. The cost of hardware-native control is engineering effort: writing every operation by hand for each kernel and backend is laborious. Exposing recurring operations as tile primitives alleviates this, so authors reuse a dispatched implementation instead of re-writing the same data movement or matrix multiply each time.
- New hardware enters as intrinsics first, tile primitives later. A new feature can be used immediately as a native intrinsic — a thin, backend-specific wrapper over a single hardware operation. Once the usage pattern stabilizes across kernels, it can be promoted to a tile primitive: a layout-aware operation that dispatches across scopes, operands, and backends. The core abstraction stays small, and adding an intrinsic for a new feature never breaks existing ones.
The result is a DSL and compiler stack that can grow with the hardware. This is the core design philosophy behind TIRx: keep the foundation small and explicit, and let the backend library evolve as new accelerator generations arrive.
This places TIRx below systems like TileLang, which also lowers the boundary relative to Triton by exposing memory scopes and pipelining, while still leaving layout inference and thread binding to the compiler. TIRx deliberately leaves those higher-level concerns outside its core and provides a minimal foundation that such systems can build on; we are working with the TileLang community to bring TIRx as a new minimal foundation to support TileLang compilation.
The same small, explicit foundation is what lets one design serve several kinds of users who pursue peak performance while reducing engineering effort as much as possible: expert-written production kernels, agent-generated kernels, and megakernel systems, each of which needs both control at the native level and recurring operations the compiler can see.
The rest of this post walks through the programming model and then through each of these directions in turn.
The TIRx Programming Model
Here is what that boundary looks like in practice. A TIRx program reads as a structured native kernel: loops, branches, tensors, synchronization, pipeline state, and backend intrinsics are written directly. Tile primitives appear where a recurring hardware operation should become reusable and dispatchable. Three ingredients carry most of the model.
Execution scope decides who runs an operation and at what granularity. Two things select it: control flow, which picks the hardware role entering a region, and the primitive namespace, which sets the granularity of the call.

An unqualified Tx.* call runs at thread level; Tx.wg.* runs at warpgroup level. A predicate such as T.ptx.elect_sync() can narrow a thread-level call further, down to a single issuing thread.
Tensor layout describes where a logical tensor lives through a storage-first interface. A tile may sit in global memory, shared memory, registers, tensor memory, or accelerator SRAM. The user declares where each tile lives and how its elements are spread across lanes, warps, and registers; that declaration stays attached to the tile. When a primitive is called, the compiler reads those declarations to choose an implementation. A layout is a storage description, not a loop-transformation utility: the user may construct a tile’s layout, but never uses layouts to transform loops.
Tile primitive dispatch turns one call into native IR. From the operand layouts, the execution scope, and the target, or an explicit dispatch= hint, it selects the matching implementation: a copy from global to shared resolves to TMA, shared to register to ldmatrix, and tensor memory to register to tcgen05.ld; a matrix multiply resolves to WGMMA, tcgen05, or a systolic-array instruction. Dispatch then generates the loops and addressing needed to apply that instruction across the whole tile.
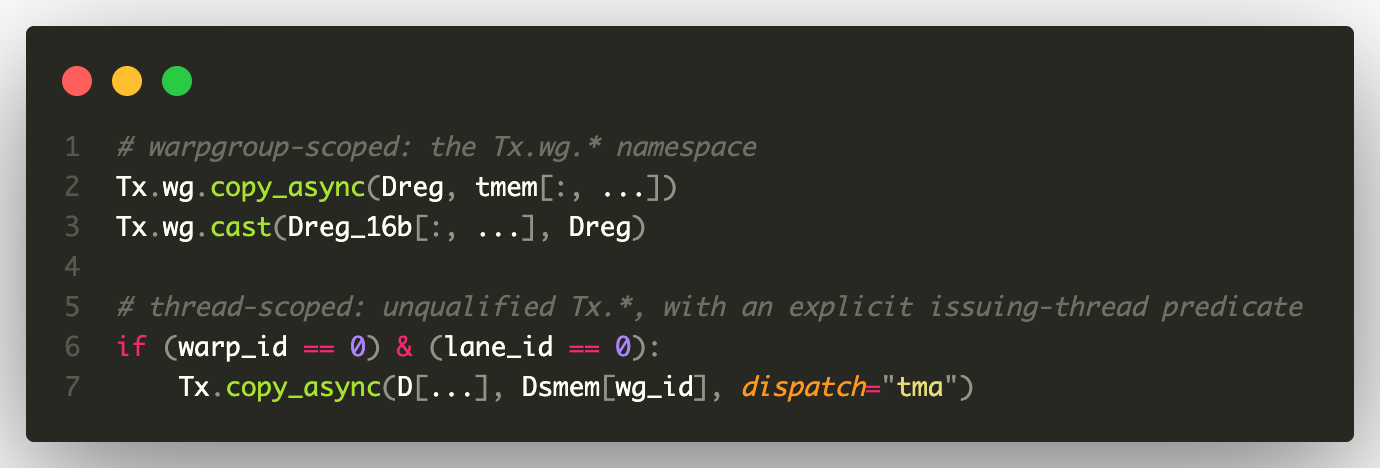
These ingredients combine wherever scope matters. In the GEMM epilogue below, warpgroup-scoped and thread-scoped primitives sit in the same region: the Tx.wg.* calls move and cast a tile across the warpgroup, while a final thread-scoped Tx.copy_async, guarded by an explicit issuing-thread predicate, performs the TMA store.
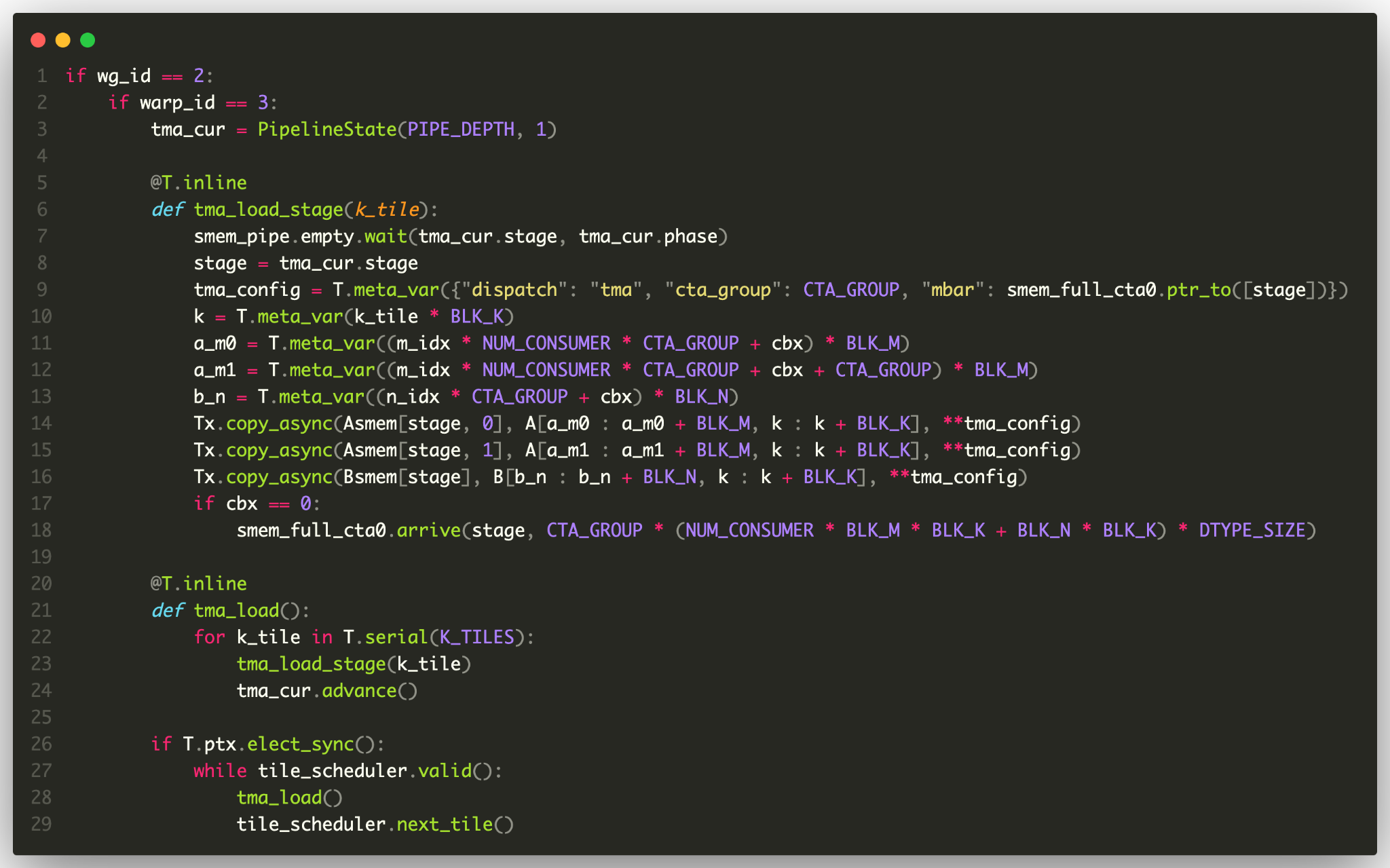
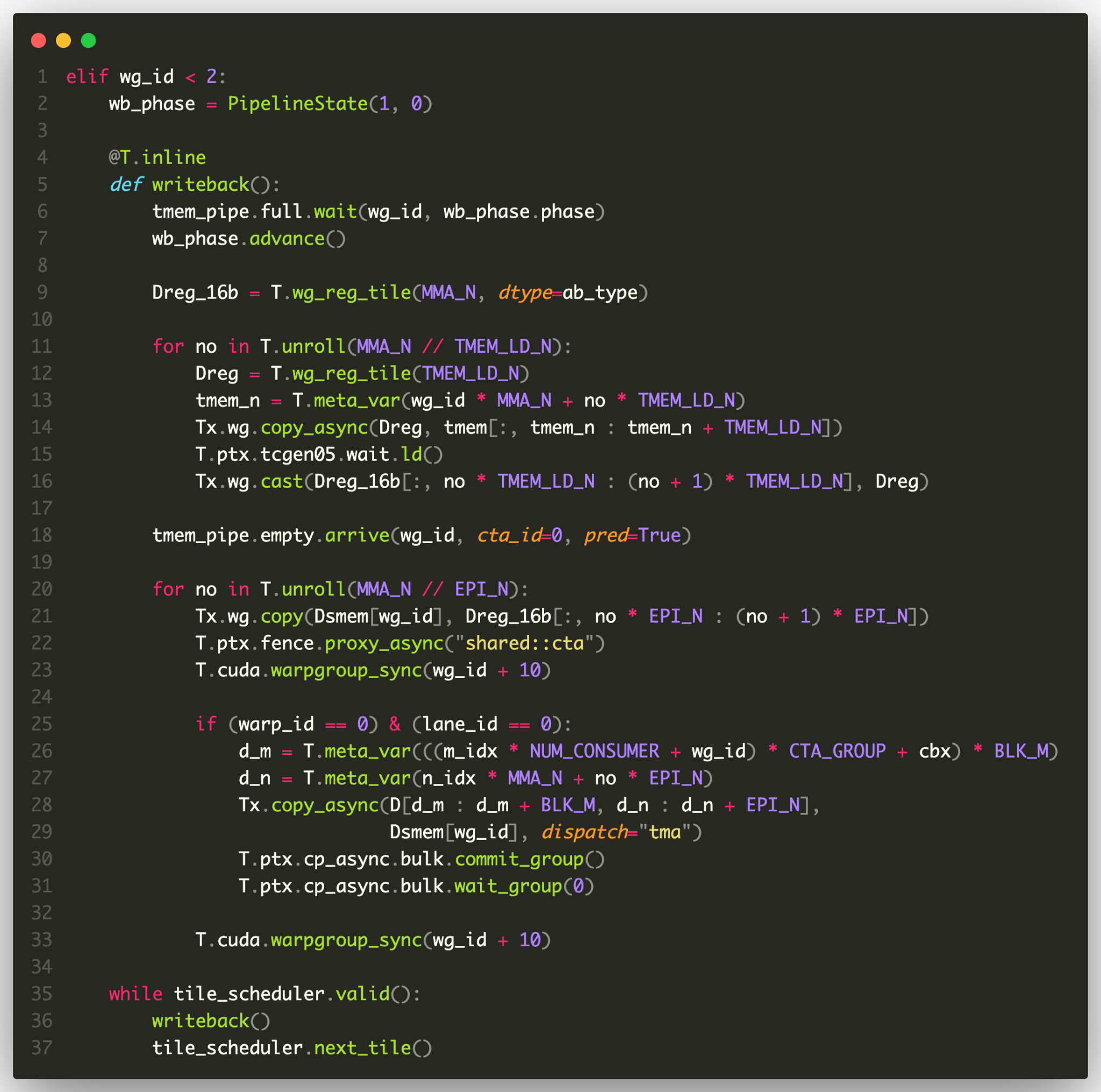
The excerpts above are simplified. For the full picture, here are two roles from a complete FP16/BF16 GEMM kernel — a TMA producer and the tensor-memory writeback. You do not need to read them line by line. The point is that everything to do with orchestration (pipeline state, barrier protocol, role selection, low-level synchronization intrinsics like tcgen05.wait and cp_async.bulk) stays in ordinary source code, while the recurring data movement appears as tile primitives whose lowering is selected from scope, layout, and dispatch configuration.
Of the three ingredients, layout involves the most design decisions, so it is worth a closer look.
A Storage-First Interface for Tensor Layouts
TIRx treats layout as a first-class representation of tensor storage. Readers familiar with CuTe will recognize the territory: both systems use layout to describe how tensor data maps onto hardware resources, but CuTe exposes layout as a programmable interface for deriving how tile work is partitioned across threads, while TIRx uses layout as a storage contract consumed by primitive dispatch.
A TIRx layout maps a logical tensor index to physical coordinates on named axes. The model generalizes shape-stride layout by attaching strides to semantic hardware axes and by adding explicit shard, replica, and offset components. Shard describes how logical elements are partitioned across physical axes. Replica describes where the same logical element is replicated. Offset describes where physical placement begins. Specifically,
- D (Shard). A list of one or more iterators, each with an extent and a stride on some axis. D partitions the logical index across these iters and produces a base coordinate. This generalizes shape-stride to multiple axes.
- R (Replica). A set of replication iterators that enumerate offsets in hardware space, independent of the logical index. Adding each element of this set to the D result yields replication or broadcasting.
- O (Offset). A fixed coordinate offset (one integer per axis) is added to every result. This places data at a specific base position or reserves exclusive resources.
A concrete example of the TIRx layout Python API is:
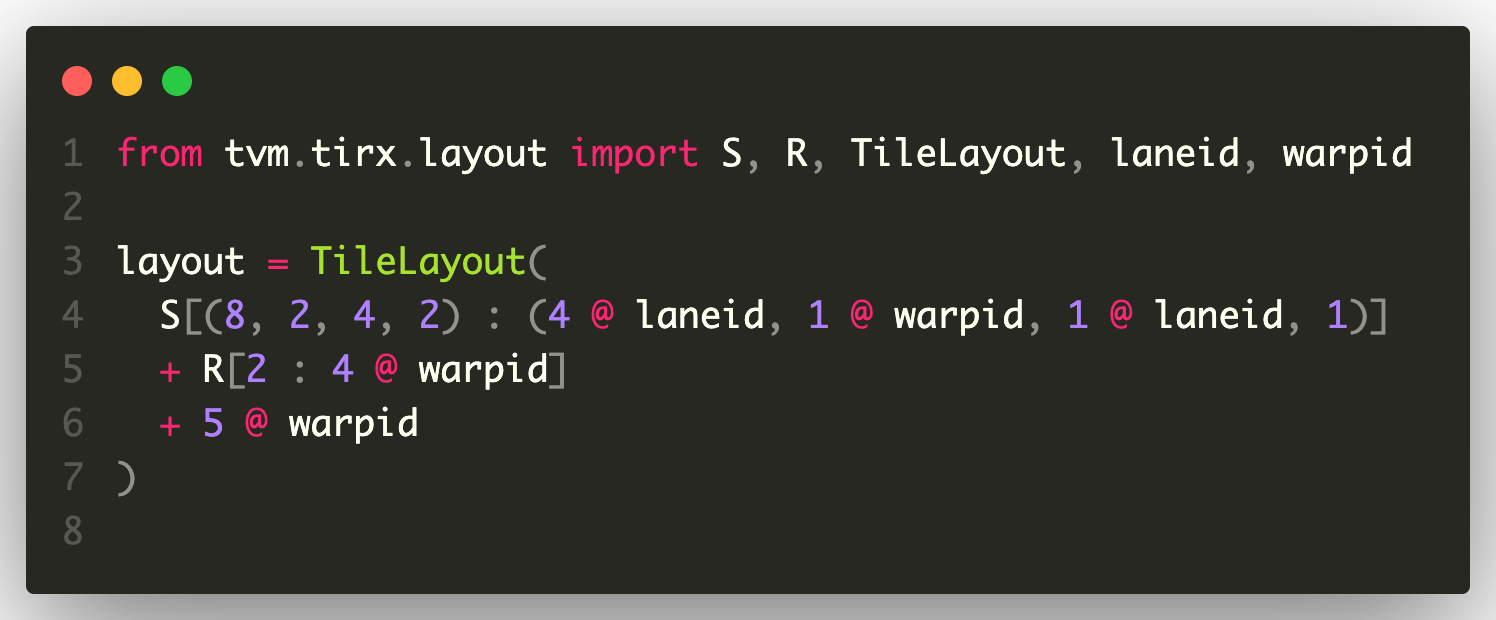
This represents a logical tile distributed over lanes and warps, replicated across another warpgroup, and placed at an offset on the warp axis. Given a logical coordinate (i, j) in (8, 16) shape space, it maps to the warp, lane, and reg axes, respectively, by computing
\[\begin{aligned} L(i,j)_{(8,16)} &= L(i\cdot 16 + j) && \text{(flatten)} \\ &= L\bigl(i,\ \lfloor j/8\rfloor,\ \lfloor j/2\rfloor\,\%\,4,\ j\,\%\,2\bigr) && \text{(unflatten)} \end{aligned}\] \[\begin{cases} @\mathrm{warp}:\ \{\,\lfloor j/8\rfloor + 5 + 4r \mid r \in [0,2)\,\} \\ @\mathrm{lane}:\ 4i + \lfloor j/2\rfloor\,\%\,4 \\ @\mathrm{reg}:\ \ j\,\%\,2 \end{cases}\]For example, element 57 at logical (3, 9) maps to:
- base location: 6@warpid, 12@laneid, 1@m
- owners (×2 via replica): { warpid=6 laneid=12 }, { warpid=10 laneid=12 }
(Open the interactive demo and click element 57 to see exactly these owners.)
▶ Open the interactive layout demo ↗
TIRx’s layout interface is built around four design choices.
1. Layout is a storage contract, not a work-partitioning interface.
In CuTe, layout is not only a representation of data placement; it is also part of the programming interface for deriving how tile operations are distributed across threads. Users compose, tile, and partition layouts to express data and work distribution for copy and compute operations. TIRx draws the boundary differently. Users describe the storage layout of each tile and call tile primitives over those tiles. The layout records how logical tensor coordinates map to physical hardware coordinates, including sharding, replication, and offset; it is not the surface used to construct the execution partitioning. When a primitive is lowered, dispatch uses the operand layouts, execution scope, and backend target to generate the thread partitioning, loop nest, addressing, and instruction sequence. In this sense, TIRx layout only needs to represent storage precisely; the transformation logic lives inside primitive dispatch rather than in user-written layout composition.
2. Layout maps logical tensor coordinates to physical hardware coordinates.
Explicit replica and offset structure come from the designated logical-to-physical formulation. One alternative way to formalize layouts is to map physical locations to logical coordinates, such that replication—one logical element stored in multiple physical locations—can still be defined as a point-valued function. However, for tensors that span physical locations in a strided pattern, some physical locations may not have a well-defined mapping.
3. Layout supports general shapes.
Modern kernels frequently use shapes that do not fit a power-of-two-only representation. Global tensors, multi-stage shared-memory buffers, tensor-memory tiles, accelerator scratchpads, and distributed tensors all produce general shapes in practice. TIRx layout therefore starts from general shape support instead of treating it as a special case. This matters for block-scaled GEMM scale-factor tiles, Blackwell tensor memory, and accelerator memories with native multi-dimensional addressing.
4. Layout uses named hardware axes.
Another possible design is to map logical coordinates to a generic pair such as (t, m), leaving the meaning of t and m to be recovered from context. Disambiguating such cases would require the compiler to consult additional contextual information carried by the tensor or rely on extra conventions in the programming model—for example, that the meaning of t is inherited from the execution scope at the tensor’s definition site. TIRx makes the hardware resource explicit in the layout itself. Axes such as laneid, warpid, tid_in_wg, Col, Lane, P, F, and pid carry semantic meaning. This makes layouts easier to read, removes context-dependent interpretation, and gives tile primitive dispatch the information it needs to check legality and select how to carry it out. It also decouples the layout from the programming model: because a layout names its hardware axes explicitly, it carries complete information on its own and is not tied to any particular programming model.
A Lightweight Compiler Backend
TIRx keeps the required lowering path focused. After parsing, a program consists of hardware-native IR plus unresolved tile primitive calls. The compiler resolves those calls locally: each primitive is dispatched according to its operands, layouts, execution scope, and target backend, and is replaced by native IR fragments such as loops, address calculations, memory-scope operations, synchronization, and intrinsic calls. After primitive dispatch, the program is already a native kernel IR and can be translated directly to backend code (CUDA C++/PTX).
This design keeps heavy optimization passes out of the critical path for expressing new kernels. Automatic warp specialization, layout inference across operators, schedule transformation, automatic tensor allocation, pipeline search, and cost-model-driven tuning are all valuable, but they tend to be tightly coupled to specific kernel families and hardware generations. When they become mandatory compiler stages, each new kernel pattern or hardware feature can require substantial pass redesign before users can access it productively.
TIRx instead treats these techniques as optional layers above a direct lowering path: they can improve performance, guide search, or automate common patterns, but the core DSL does not depend on them to represent a new program.
Performance
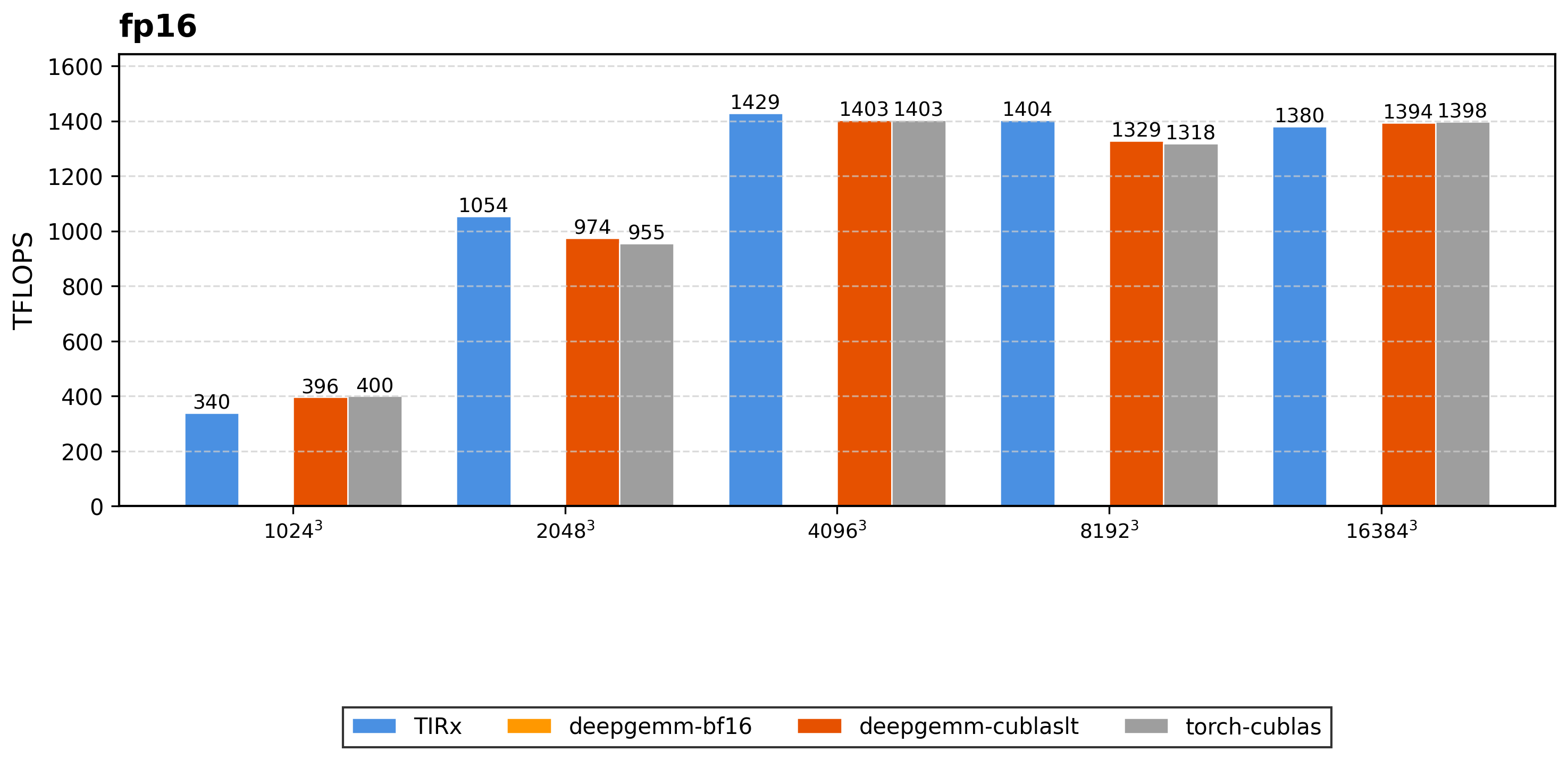
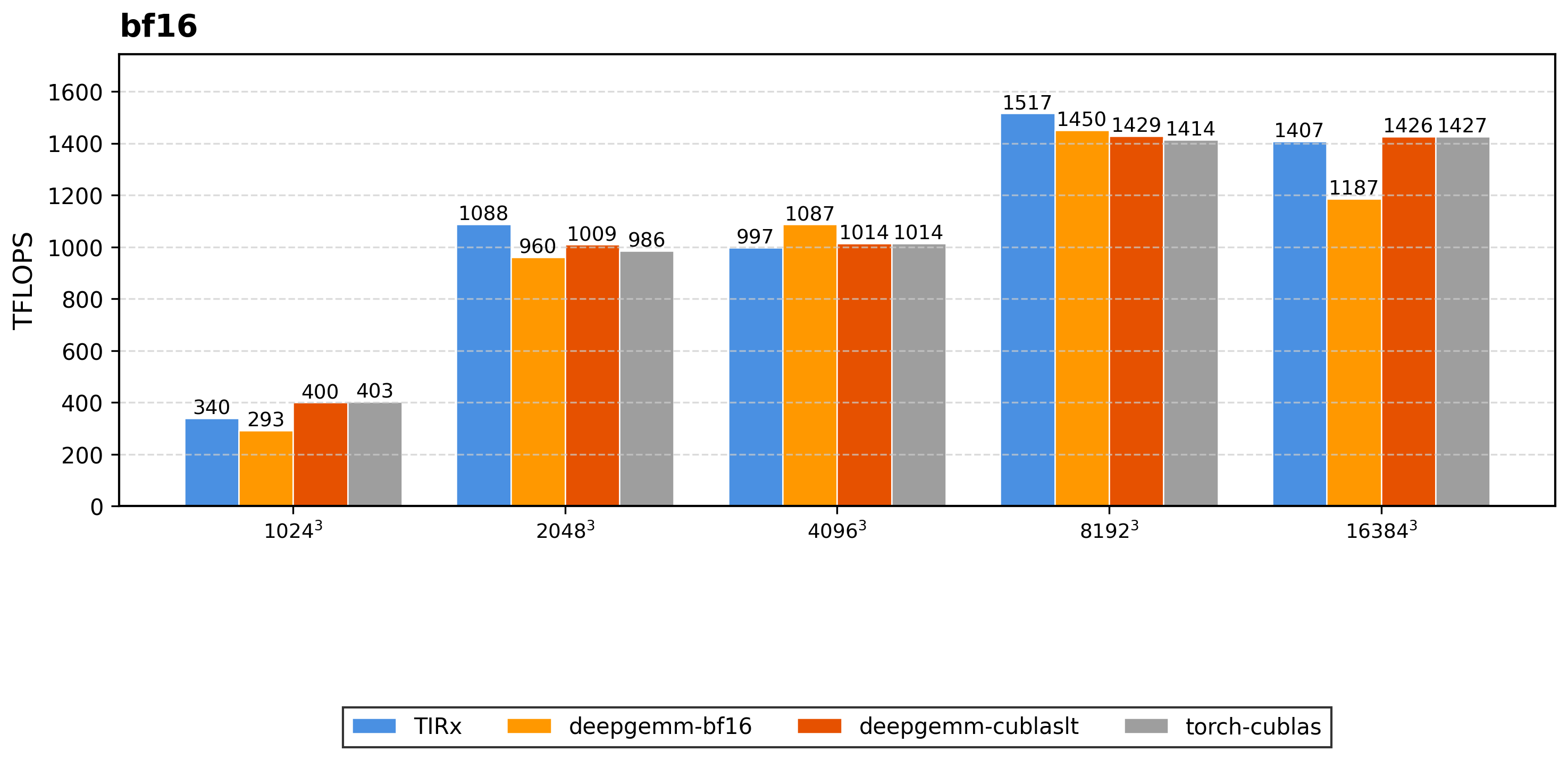
We evaluate TIRx on 54 configurations spanning dense GEMM, block-scaled low-precision GEMM, and attention, measured on an NVIDIA B200 (SM100) and reported as sustained TFLOPS. On each configuration we compare TIRx to the fastest of the applicable state-of-the-art baselines.
Dense GEMM (FP16 / BF16). TIRx tracks the best cuBLAS and DeepGEMM baselines across square sizes from 1024³ to 16384³, reaching 1517 TFLOPS on BF16 8192³ and 1404 TFLOPS on FP16 8192³, or 0.96× and 0.95× the best baseline on those shapes (DeepGEMM-BF16 and DeepGEMM cuBLASLt).
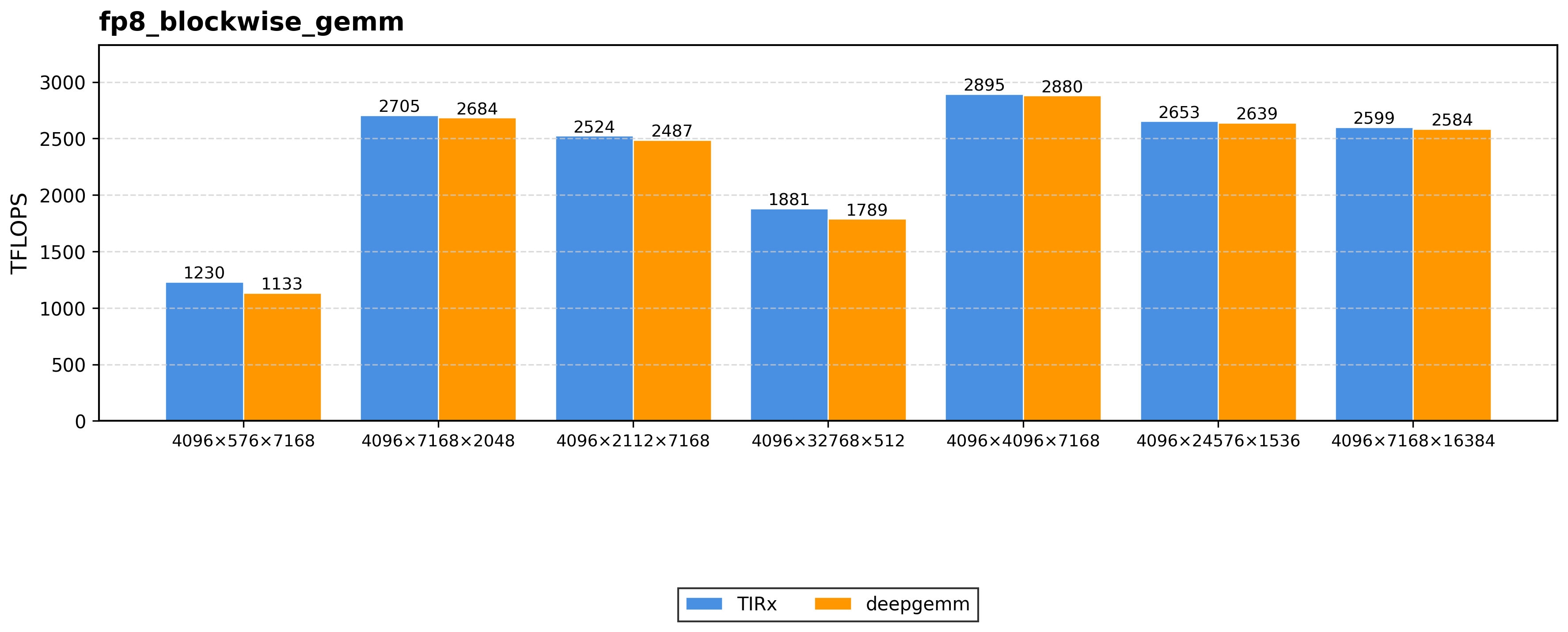
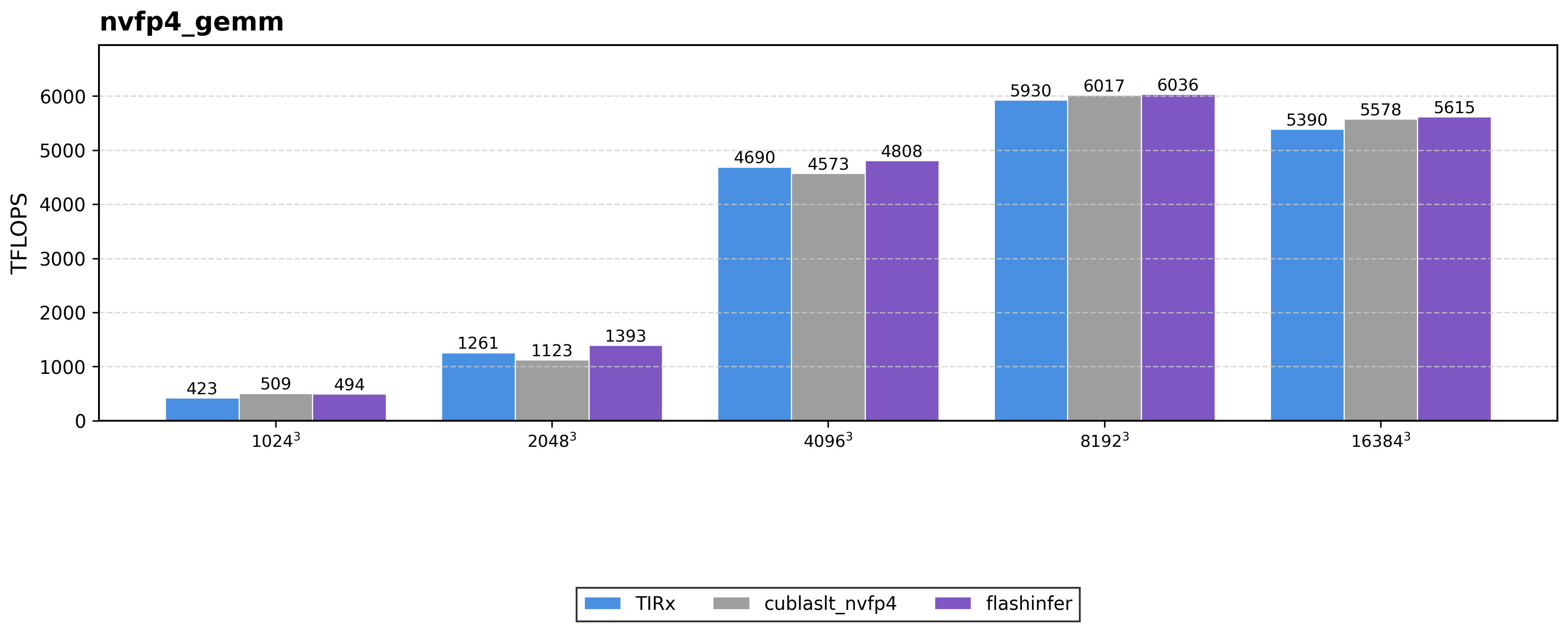
Block-scaled low-precision GEMM (FP8 / NVFP4). For FP8 blockwise GEMM, TIRx sustains 2895 TFLOPS on 4096×4096×7168, matching DeepGEMM within 0.99×. On NVFP4 8192³, TIRx achieves 5930 TFLOPS, within 2% of the best baseline (cuBLASLt NVFP4 and FlashInfer).
FlashAttention-4 (causal / non-causal). TIRx is competitive with flashattn_sm100 (CuTeDSL) at long sequence lengths. At s4096 and s8192 with 32 query heads (non-causal), TIRx delivers 1340 and 1328 TFLOPS versus 1330 and 1327 for the CuTeDSL baseline (0.99× and 1.00×); the causal variant at s4096 reaches 1236 TFLOPS (0.97×). Across all 32 FA4 configurations, non-causal throughput ranges from 580 to 1358 TFLOPS (median 1277) and causal from 277 to 1326 TFLOPS (median 1075); the lower absolute numbers at short sequences (433 TFLOPS at s1024 causal) follow from the S² FLOP scaling, not degraded long-context performance.
Experimental setup.
- Hardware and software: 4× NVIDIA B200 (SM100), driver 595.58.03, CUDA 13.2, PyTorch 2.12.0+cu132 (torch git 7661cd9c6b84).
- Workloads (54 configurations): FP16 and BF16 GEMM (5 square sizes each, 1024³ to 16384³), FP8 blockwise GEMM (7 DeepGEMM-style shapes), NVFP4 GEMM (5 square sizes), and FlashAttention-4 (32 configs: sequence length 1024 to 8192, heads 4/8/16/32, causal and non-causal).
- Protocol: timed with Proton (warmup 100, repeat 30, 5 independent rounds averaged). TFLOPS = FLOPs / latency, with 2MNK for GEMM and 4·B·H·S²·D for FA4 (B=1, D=128; causal configs scaled by 0.5).
- Baselines (local editable installs, pinned by commit):
torch-cublas: PyTorch 2.12.0+cu132 / cuBLASdeepgemm/deepgemm-bf16/deepgemm-cublaslt: DeepGEMM commit 714dd1a4 (2026-05-11), 17 commits after v2.1.1.post3flashinfer: FlashInfer commit bff85f34 (2026-05-22), tag nightly-v0.6.12-20260523flashattn_sm100(CuTeDSL): FlashAttention commit 3da76cdb (2026-05-22), tag fa4-v4.0.0.beta14cublaslt_nvfp4: cuBLASLt reference in tirx-kernels, same CUDA 13.2 stack
What TIRx Enables
TIRx is immediately useful as a kernel DSL. The same structure also helps with three things that are becoming important for ML systems: supporting new hardware, building megakernels, and agentic kernel programming.
A Stable Extension Boundary for Future Hardware

By design, TIRx treats new hardware support as a staged process rather than a redesign of the DSL. When a feature first appears, it can be exposed directly as a backend intrinsic so kernel authors can use it immediately. Once the same usage pattern repeats across kernels, it can be promoted into a tile primitive with layout helpers, legality checks, and optimized dispatch. This lets the system support a new generation early, then consolidate recurring patterns into reusable libraries.
Future hardware should grow the backend library, not the core language. This separation keeps the TIRx core small. New memory spaces become storage scopes and layout axes; new cooperation mechanisms become scope constructs and validation rules; new instructions become intrinsics and primitive implementations. Higher-level automation—schedule search, pipelining, performance models, and agentic tuning—can then optimize over these explicit building blocks instead of requiring the core compiler to predict every hardware pattern upfront.
Megakernels and Composable Tile Tasks
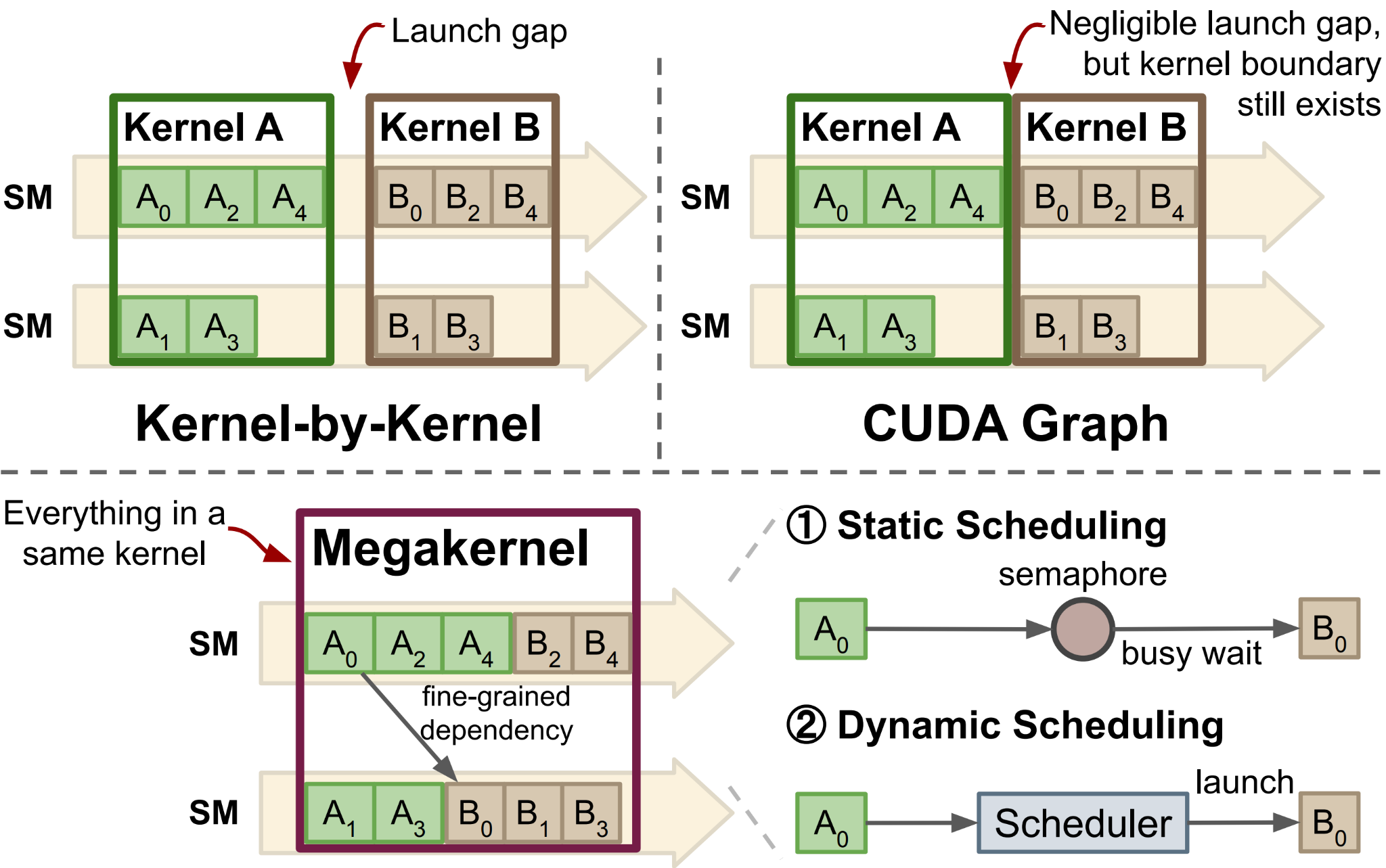
Megakernels may change the shape of kernel libraries. Instead of exposing optimized implementations only as opaque host-launched kernels, future libraries may expose efficient device-side tasks: GEMM tiles, attention tiles, reduction tiles, communication chunks, epilogue tiles, and accelerator-specific data movement tasks. A megakernel DSL or compiler can then stitch these tasks together through an in-kernel schedule, forming a larger persistent kernel from reusable high-performance building blocks.
This creates a new requirement for the DSL used to write those tasks. Each task must still capture state-of-the-art intra-task implementation details: memory movement, synchronization, pipeline state, warpgroup roles, tensor-memory usage, backend intrinsics, and layout choices. At the same time, the task needs enough IR structure to be stitched into a larger program: inputs, outputs, memory scopes, layouts, synchronization behavior, and execution ownership cannot be hidden behind an opaque kernel boundary.
TIRx is designed for this layer for two reasons. First, the performance of a megakernel depends on the performance of its tasks: TIRx tasks keep pipeline structure, synchronization, role assignment, and backend intrinsics under the author’s control, so each task can carry a state-of-the-art implementation. Second, TIRx tasks exist as compiler IR rather than as separately compiled kernels, so a megakernel compiler can transform them directly: stitching and scheduling can be organized as passes over task IR (re-offsetting shared memory, renaming barriers, reassigning warp roles, interleaving pipelines across tasks), which a separately compiled, opaque kernel cannot support.
TIRx is not a full megakernel compiler by itself; task graphs, dependency tracking, in-kernel scheduling, and runtime policies belong to the megakernel system above it. We have already been exploring this direction on top of TIRx and built Event Tensor (MLSys ‘26, https://arxiv.org/pdf/2604.13327), which uses tiled tasks and first-class dependency tensors to compile dynamic megakernels. It illustrates the kind of system TIRx is meant to support: a higher-level megakernel compiler manages task dependencies and scheduling. At the same time, TIRx provides the substrate for authoring high-performance tile tasks that are both hardware-native and composable. We will be working on bringing Event Tensor integration into TIRx in follow-up releases.
Agentic Kernel Programming
Agentic kernel programming needs support at two levels: the compiler stack must be easy for agents and tools to instrument, and the DSL must expose a search space that is structured enough to guide kernel exploration.
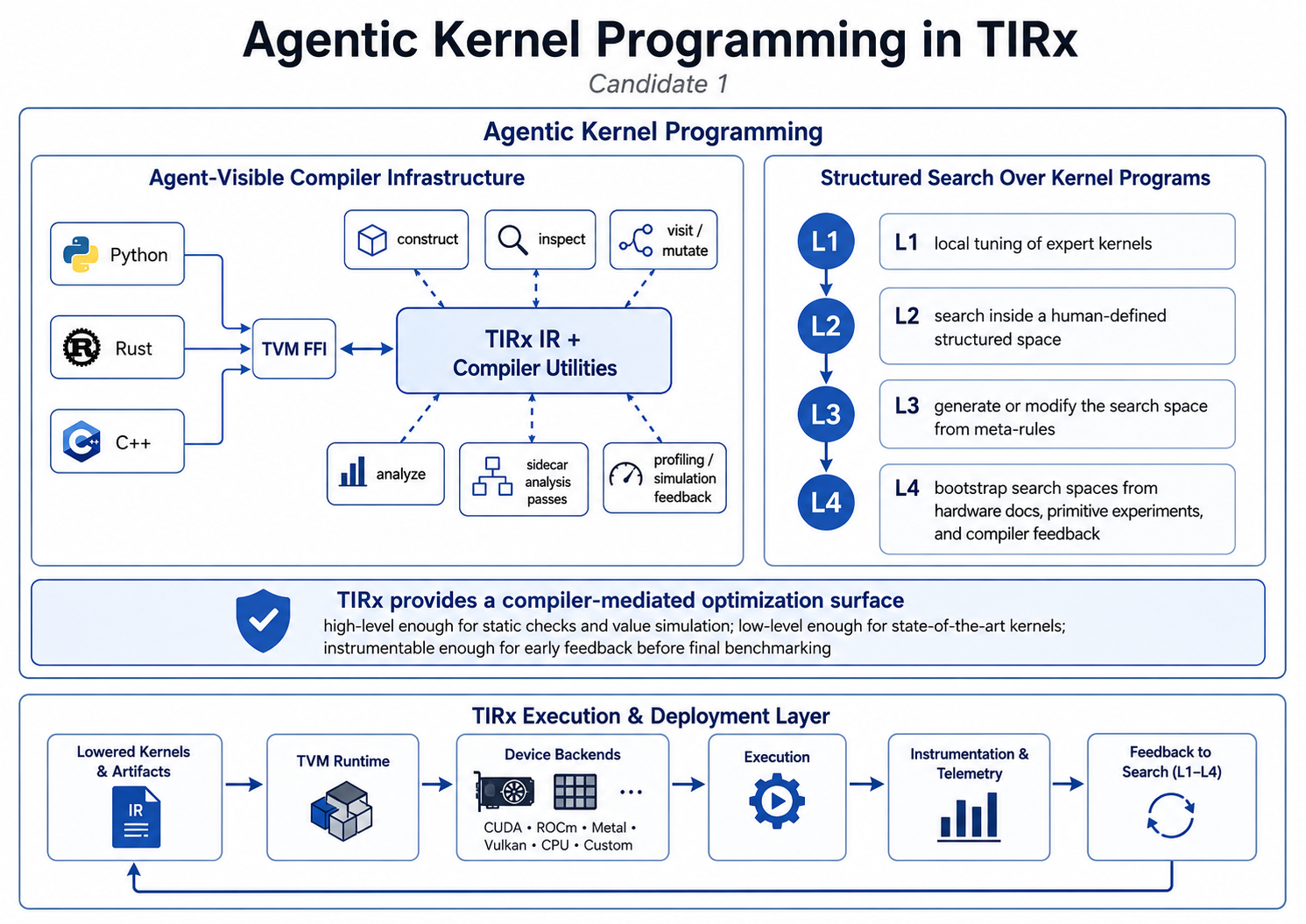
Agent-visible compiler infrastructure. The first layer is compiler toolability. An agent workflow should be able to construct, inspect, visit, mutate, and analyze compiler IR without turning every new experiment into a full compiler rebuild. TIRx is built to expose its IR objects and compiler utilities through TVM FFI across Python, C++, and Rust. This makes it practical to plug in sidecar analysis passes in the language best suited for the task: layout inspection in Python, fast simulation or static analysis in Rust, backend-specific checks in C++, or lightweight mutation passes for rapid search.
This matters because agentic optimization will likely depend on fast iteration. Agents need to test hypotheses, mutate programs, run legality checks, inspect intermediate IR, and attach profiling or simulation feedback. A compiler stack that exposes IR and passes through a language-agnostic FFI gives agents a practical substrate for this kind of experimentation, instead of forcing every new analysis or mutation strategy into the core compiler build.
Structured search over kernel programs. The second layer is the search space itself. Earlier automatic kernel optimization systems such as Ansor and MetaSchedule framed the problem around structured search: construct a search space that mostly contains algorithmically valid programs, sample candidates from that space, and then perform local tuning to improve performance. Agentic kernel optimization can be viewed as a more flexible version of the same idea, in which an agent controls how candidates are generated, mutated, refined, and evaluated.
We can think of this progression in several levels.
- L1: An agent locally tunes an already optimized expert kernel, which is where many current kernel-agent systems operate.
- L2: An agent samples kernel candidates from a human-defined structured search space and then performs local performance tuning.
- L3: An agent starts to generate or modify the search space from human-provided meta-rules.
- L4: The long-term goal is for an agent to bootstrap useful search spaces from hardware documentation, primitive experiments, and compiler feedback.
TIRx is designed to support the middle of this spectrum. It combines high-level tile primitives with full hardware-native access, so an agent can start from a structured program written mostly in primitives and gradually refine it toward a more specialized implementation. This high-level subset gives the compiler a program structure that can provide early feedback on primitive dispatch, layout compatibility, synchronization structure, race conditions, and value-level simulation against a reference.
This is the key advantage for agentic search. If the only reward comes after compiling, running, checking correctness, and benchmarking on hardware, the signal is sparse and expensive. A structured TIRx program gives the agent denser reward signals along the way: whether the program is well formed, whether the synchronization pattern is valid, whether memory accesses are race-free, whether simulated values match the intended computation, and whether resource or performance models predict a useful direction.
In this view, TIRx is not just a target language for generated kernels. It is something an agent can optimize against with the compiler’s help: high-level enough that the compiler can run static checks and simulate values, low-level enough to express state-of-the-art implementations, and open enough that an agent can inspect and mutate it for feedback before the final benchmark.
Contributing
TIRx is an open compiler foundation. The core abstraction boundary is intentionally small, but the ecosystem around it can grow in several directions. Feel free to try out TIRx and contribute to the compiler and the community projects.
Acknowledgement
TIRx would not exist without Apache TVM, on whose compiler infrastructure it is built. Beyond that foundation, its design has been shaped by a long line of systems work, including NumPy, CuTe, Triton, ThunderKittens, and TileLang. We thank the FlashInfer, FlashInfer-Bench, and TileLang teams and the Apache TVM community for helpful technical discussions.