Tensor and DLPack#
At runtime, TVM-FFI often needs to accept tensors from many sources:
Frameworks (e.g. PyTorch, JAX, PaddlePaddle) via
array_api.array.__dlpack__();C/C++ callers passing
DLTensor*;Tensors allocated by a library but managed by TVM-FFI itself.
TVM-FFI standardizes on DLPack as the lingua franca: tensors are built on top of DLPack structs with additional C++ convenience methods and minimal extensions for ownership management.
Tip
Prefer tvm::ffi::TensorView or tvm::ffi::Tensor in C++ code;
they provide safer and more convenient abstractions over raw DLPack structs.
This tutorial covers common usage patterns, tensor classes, and how tensors flow across ABI boundaries.
Glossary#
- DLPack
A cross-library tensor interchange standard defined in the small C header
dlpack.h. It defines pure C data structures for describing n-dimensional arrays and their memory layout, includingDLTensor,DLManagedTensorVersioned,DLDataType,DLDevice, and related types.- View (non-owning)
A “header” that describes a tensor but does not own its memory. When a consumer receives a view, it must respect that the producer owns the underlying storage and controls its lifetime. The view is valid only while the producer guarantees it remains valid.
- Managed object (owning)
An object that includes lifetime management, using reference counting or a cleanup callback mechanism. This establishes a contract between producer and consumer about when the consumer’s ownership ends.
Note
As a loose analogy, think of view vs. managed as similar to
T* (raw pointer) vs. std::shared_ptr<T> (reference-counted pointer) in C++.
Common Usage#
This section introduces the most important APIs for day-to-day use in C++ and Python.
Kernel Signatures#
A typical kernel implementation accepts TensorView parameters,
validates metadata (dtype, shape, device), and then accesses the data pointer for computation.
Use TVM_FFI_THROW to report validation errors (see Exception Handling):
#include <tvm/ffi/tvm_ffi.h>
void MyKernel(tvm::ffi::TensorView input, tvm::ffi::TensorView output) {
// Validate dtype & device
if (input.dtype() != DLDataType{kDLFloat, 32, 1})
TVM_FFI_THROW(TypeError) << "Expect float32 input, but got " << input.dtype();
if (input.device() != DLDevice{kDLCUDA, 0})
TVM_FFI_THROW(ValueError) << "Expect input on CUDA:0, but got " << input.device();
// Access data pointer
float* input_data_ptr = static_cast<float*>(input.data_ptr());
float* output_data_ptr = static_cast<float*>(output.data_ptr());
Kernel<<<...>>>(..., input_data_ptr, output_data_ptr, ...);
}
On the C++ side, the following APIs are available to query a tensor’s metadata:
TensorView::shape()andTensor::shape()Shape array. For kernels exported as TVM-FFI functions, see Function and Module.
TensorView::dtype()andTensor::dtype()element data type
TensorView::data_ptr()andTensor::data_ptr()base pointer to the tensor’s data
TensorView::device()andTensor::device()device type and id
TensorView::byte_offset()andTensor::byte_offset()byte offset to the first element
TensorView::ndim()andTensor::ndim()number of dimensions (
ShapeView::size)TensorView::numel()andTensor::numel()total number of elements (
ShapeView::Product)
PyTorch Interop#
On the Python side, tvm_ffi.Tensor is a managed n-dimensional array that:
can be created via
tvm_ffi.from_dlpack(ext_tensor, ...)to import tensors from external frameworks, e.g., PyTorch, JAX, PaddlePaddle, NumPy/CuPy;implements the DLPack protocol so it can be passed back to frameworks without copying, e.g.,
torch.from_dlpack().
The following example demonstrates a typical round-trip pattern:
import tvm_ffi
import torch
x_torch = torch.randn(1024, device="cuda")
x_tvm_ffi = tvm_ffi.from_dlpack(x_torch, require_contiguous=True)
x_torch_again = torch.from_dlpack(x_tvm_ffi)
In this example, tvm_ffi.from_dlpack() creates x_tvm_ffi, which views the same memory as x_torch.
Similarly, torch.from_dlpack() creates x_torch_again, which shares the underlying buffer with both
x_tvm_ffi and x_torch. No data is copied in either direction.
C++ Allocation#
TVM-FFI is not a kernel library and is not linked to any specific device memory allocator or runtime. However, it provides standardized allocation entry points for kernel library developers by interfacing with the surrounding framework’s allocator - for example, using PyTorch’s allocator when running inside a PyTorch environment.
Env Allocator. Use Tensor::FromEnvAlloc() along with C API
TVMFFIEnvTensorAlloc() to allocate a tensor using the framework’s allocator.
Tensor tensor = Tensor::FromEnvAlloc(
TVMFFIEnvTensorAlloc,
/*shape=*/{1, 2, 3},
/*dtype=*/DLDataType({kDLFloat, 32, 1}),
/*device=*/DLDevice({kDLCPU, 0})
);
In a PyTorch environment, this is equivalent to torch.empty().
Warning
While allocation APIs are available, it is generally recommended to avoid allocating tensors
inside kernels. Instead, prefer pre-allocating outputs and passing them as
tvm::ffi::TensorView parameters. This approach:
avoids memory fragmentation and performance pitfalls,
prevents CUDA graph incompatibilities on GPU, and
allows the outer framework to control allocation policy (pools, device strategies, etc.).
Custom Allocator. Use Tensor::FromNDAlloc(custom_alloc, ...),
or its advanced variant Tensor::FromNDAllocStrided(custom_alloc, ...),
to allocate a tensor with a user-provided allocation callback.
The following example uses cudaMalloc/cudaFree as custom allocators for GPU tensors:
struct CUDANDAlloc {
void AllocData(DLTensor* tensor) {
size_t data_size = ffi::GetDataSize(*tensor);
void* ptr = nullptr;
cudaError_t err = cudaMalloc(&ptr, data_size);
TVM_FFI_ICHECK_EQ(err, cudaSuccess) << "cudaMalloc failed: " << cudaGetErrorString(err);
tensor->data = ptr;
}
void FreeData(DLTensor* tensor) {
if (tensor->data != nullptr) {
cudaError_t err = cudaFree(tensor->data);
TVM_FFI_ICHECK_EQ(err, cudaSuccess) << "cudaFree failed: " << cudaGetErrorString(err);
tensor->data = nullptr;
}
}
};
ffi::Tensor cuda_tensor = ffi::Tensor::FromNDAlloc(
CUDANDAlloc(),
/*shape=*/{3, 4, 5},
/*dtype=*/DLDataType({kDLFloat, 32, 1}),
/*device=*/DLDevice({kDLCUDA, 0})
);
C++ Stream Handling#
Stream context is essential for GPU kernel execution. While CUDA does not have a global context for
default streams, frameworks like PyTorch maintain a “current stream” per device
(torch.cuda.current_stream()), and kernel libraries must read this stream from the embedding environment.
As a hardware-agnostic abstraction layer, TVM-FFI is not linked to any specific stream management library. However, to ensure GPU kernels launch on the correct stream, it provides standardized APIs to obtain the stream context from the host framework (e.g., PyTorch).
Obtain Stream Context. Use the C API TVMFFIEnvGetStream() to obtain the current stream for a given device:
void func(ffi::TensorView input, ...) {
ffi::DLDevice device = input.device();
cudaStream_t stream = reinterpret_cast<cudaStream_t>(
TVMFFIEnvGetStream(device.device_type, device.device_id));
}
This is equivalent to the following PyTorch C++ code:
void func(at::Tensor input, ...) {
c10::Device device = input.device();
cudaStream_t stream = reinterpret_cast<cudaStream_t>(
c10::cuda::getCurrentCUDAStream(device.index()).stream());
}
Auto-Update Stream Context. When converting framework tensors via tvm_ffi.from_dlpack(),
TVM-FFI automatically updates the stream context to match the device of the converted tensor.
For example, when converting a PyTorch tensor on torch.device('cuda:3'), TVM-FFI automatically
captures the stream from torch.cuda.current_stream(device='cuda:3')().
Set Stream Context. Use tvm_ffi.use_torch_stream() or tvm_ffi.use_raw_stream()
to manually set the stream context when automatic detection is insufficient.
Tensor Classes#
This section defines each tensor type in the TVM-FFI C++ API and explains its intended usage. Exact C layout details are covered in Tensor Layouts.
Tip
On the Python side, only tvm_ffi.Tensor exists. It strictly follows DLPack semantics for interop and can be converted to PyTorch via torch.from_dlpack().
DLPack Tensors#
DLPack tensors come in two main flavors:
- Non-owning object,
DLTensor The tensor descriptor is a view of the underlying data. It describes the device the tensor lives on, its shape, dtype, and data pointer. It does not own the underlying data.
- Owning object,
DLManagedTensorVersioned, or its legacy counterpartDLManagedTensor It is a managed variant that wraps a
DLTensordescriptor with additional fields. Notably, it includes adeletercallback that releases ownership when the consumer is done with the tensor, and an opaquemanager_ctxhandle used by the producer to store additional context.
TVM-FFI Tensors#
Similarly, TVM-FFI defines two main tensor types in C++:
- Non-owning object,
tvm::ffi::TensorView A thin C++ wrapper around
DLTensorfor inspecting metadata and accessing the data pointer. It is designed for kernel authors to inspect metadata and access the underlying data pointer during a call, without taking ownership of the tensor’s memory. Being a view also means you must ensure the backing tensor remains valid while you use it.- Owning object,
tvm::ffi::TensorObjandtvm::ffi::Tensor Tensor, similar tostd::shared_ptr<TensorObj>, is the managed class to hold heap-allocatedTensorObj. Once the reference count drops to zero (see Reference Counting), the cleanup logic deallocates the descriptor and releases ownership of the underlying data buffer.
Note
For handwritten C++, always use TVM-FFI tensors over DLPack’s raw C tensors.
For compiler development, DLPack’s raw C tensors are recommended because C is easier to target from codegen.
The owning Tensor is the recommended interface for passing around managed tensors.
Use owning tensors when you need one or more of the following:
return a tensor from a function across ABI, which will be converted to
tvm::ffi::Any;allocate an output tensor as the producer, and hand it to a kernel consumer;
store a tensor in a long-lived object.
Tensor is an intrusive pointer of a heap-allocated TensorObj.
As an analogy to std::shared_ptr, think of
using Tensor = std::shared_ptr<TensorObj>;
You can convert between the two types:
Tensor::get()converts it toTensorObj*.GetRef<Tensor>converts aTensorObj*back toTensor.
Tensor Layouts#
Figure 1 summarizes the layout relationships among DLPack tensors and TVM-FFI tensors.
All tensor classes are POD-like; tvm::ffi::TensorObj is also a standard TVM-FFI object, typically
heap-allocated and reference-counted.
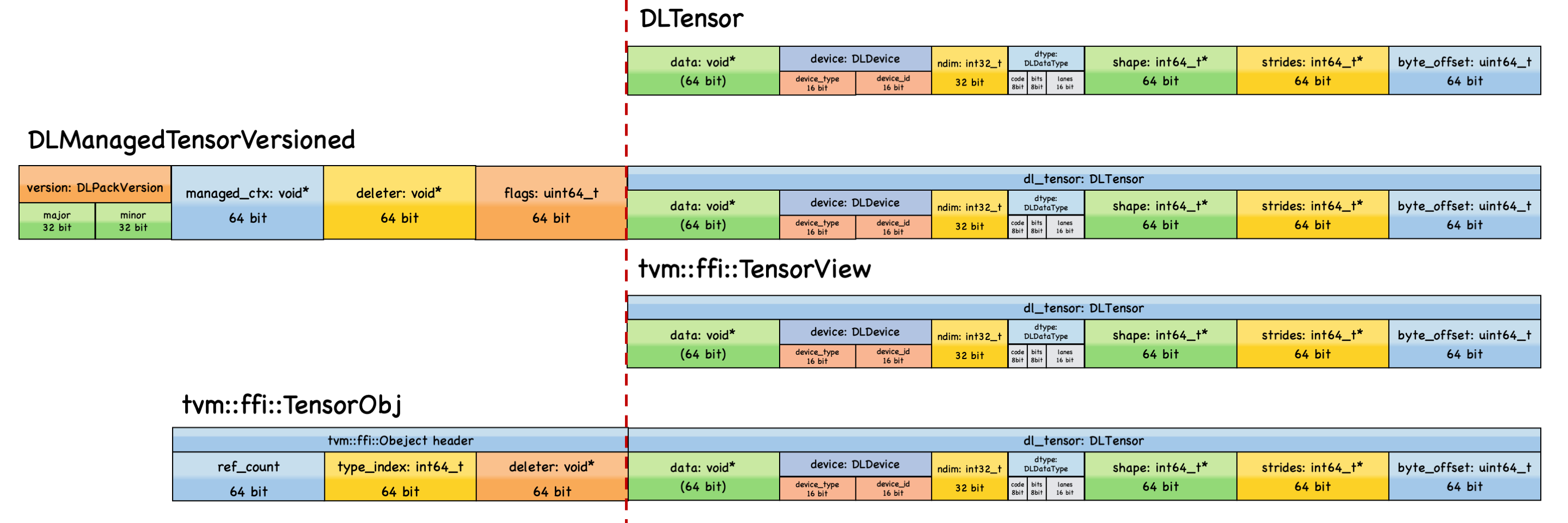
Figure 1. Layout specification of DLPack tensors and TVM-FFI tensors. All the tensor types share DLTensor as the common descriptor, while carrying different metadata and ownership semantics.#
As demonstrated in the figure, all tensor classes share DLTensor as the common descriptor.
In particular,
DLTensorandTensorViewshare the exact same memory layout.DLManagedTensorVersionedandTensorObjboth have a deleter callback to manage the lifetime of the underlying data buffer, whileDLTensorandTensorViewdo not.Compared with
TensorView,TensorObjhas an extra TVM-FFI object header, making it reference-countable via the standard managed referenceTensor.
What Tensor Is Not#
TVM-FFI is not a tensor library. While it provides a unified representation for tensors, it does not include:
kernels (e.g., vector addition, matrix multiplication),
host-device copy or synchronization primitives,
advanced indexing or slicing, or
automatic differentiation or computational graph support.
Conversion between TVMFFIAny#
At the stable C ABI boundary, TVM-FFI passes values using Any (owning)
or AnyView (non-owning). Tensors have two possible representations:
Non-owning:
DLTensor*with type indexTVMFFITypeIndex::kTVMFFIDLTensorPtrOwning:
TensorObj*with type indexTVMFFITypeIndex::kTVMFFITensor
When extracting a tensor from TVMFFIAny, check the type_index
to determine the representation before conversion.
Important
An owning tensor can be converted to a non-owning view, but not vice versa.
See Tensor for C code examples demonstrating:
Further Reading#
Object and Class: The object system that backs
TensorObjAny and AnyView: How tensors are stored in
AnycontainersFunction and Module: How tensors are passed through TVM-FFI function calls
Exception Handling: Throwing errors during tensor validation
ABI Overview: Low-level C ABI details for tensor conversion
Kernel Library Guide: Best practices for building kernel libraries with TVM-FFI
DLPack C API: The underlying tensor interchange standard